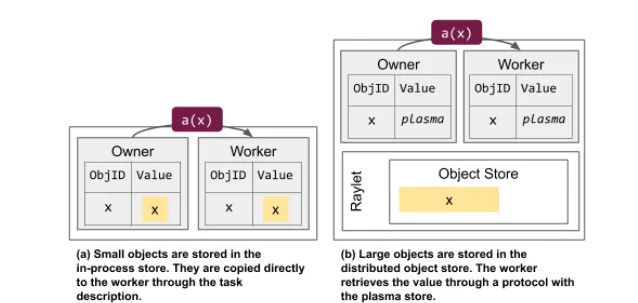
有许多简单的教程,以及Stack Overflow上的问题和答案声称Ray会以某种方式与worker共享数据,但这些都没有详细说明在哪个操作系统上会共享哪些内容。
例如,在这个SO答案中:https://stackoverflow.com/a/56287012/1382437 ,一个np数组被序列化到共享对象存储中,然后由多个worker使用,所有worker都可以访问相同的数据(代码从该答案复制):
import numpy as np
import ray
ray.init()
@ray.remote
def worker_func(data, i):
# Do work. This function will have read-only access to
# the data array.
return 0
data = np.zeros(10**7)
# Store the large array in shared memory once so that it can be accessed
# by the worker tasks without creating copies.
data_id = ray.put(data)
# Run worker_func 10 times in parallel. This will not create any copies
# of the array. The tasks will run in separate processes.
result_ids = []
for i in range(10):
result_ids.append(worker_func.remote(data_id, i))
# Get the results.
results = ray.get(result_ids)
ray.put(data)调用将数据的序列化表示放入共享对象存储,并返回其句柄/ID。
当调用worker_func.remote(data_id, i)时,worker_func将传递反序列化的数据。
但是在两者之间发生了什么?显然,data_id用于定位序列化版本的数据并对其进行反序列化。
Q1:当数据被“反序列化”时,是否总是会创建原始数据的副本?我认为是,但不确定。
一旦数据已被反序列化,它就会传递给工作进程。现在,如果需要将相同的数据传递给另一个工作进程,则有两种可能性:
Q2:当已经被反序列化的对象传递给工作进程时,它会通过另一个副本还是完全相同的对象进行传递?如果是完全相同的对象,这是使用标准的共享内存方法在进程之间共享数据吗?在Linux上,这意味着写时复制,因此这是否意味着只要对象被写入,就会创建另一个副本?
Q3:一些教程/答案似乎表明,反序列化和在工作进程之间共享数据的开销在很大程度上取决于数据类型(Numpy与非Numpy),因此细节是什么?为什么numpy数据可以更有效地共享,并且当客户端尝试写入该numpy数组时是否仍然有效(我认为始终会为该进程创建本地副本?)