我正在为我的课程项目之一,用C语言实现“朴素贝叶斯分类器”。我的项目是使用大量的训练数据实现一个文档分类应用程序(特别是垃圾邮件)。
现在我遇到了问题,因为C语言的数据类型限制,无法实现该算法。
( 我使用的算法可以在这里找到:http://en.wikipedia.org/wiki/Bayesian_spam_filtering )
问题陈述: 该算法涉及对文档中的每个单词进行处理,并计算其作为垃圾单词的概率。如果P1、P2、P3....PN是单词1、2、3......N的概率。则根据下式计算出文档是否为垃圾邮件的概率:

在这里,概率值很容易接近0.01。所以即使我使用“double”数据类型,我的计算也会失败。为了确认这一点,我编写了下面的示例代码。
#define PROBABILITY_OF_UNLIKELY_SPAM_WORD (0.01)
#define PROBABILITY_OF_MOSTLY_SPAM_WORD (0.99)
int main()
{
int index;
long double numerator = 1.0;
long double denom1 = 1.0, denom2 = 1.0;
long double doc_spam_prob;
/* Simulating FEW unlikely spam words */
for(index = 0; index < 162; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom1 = denom1*(long double)(1 - PROBABILITY_OF_UNLIKELY_SPAM_WORD);
}
/* Simulating lot of mostly definite spam words */
for (index = 0; index < 1000; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom1 = denom1*(long double)(1- PROBABILITY_OF_MOSTLY_SPAM_WORD);
}
doc_spam_prob= (numerator/(denom1+denom2));
return 0;
}
我尝试了Float、double甚至是long double数据类型,但仍然存在同样的问题。因此,假设在我正在分析的10万个单词的文档中,只有162个单词具有1%的垃圾邮件概率,而其余99838个单词明显是垃圾邮件,则由于精度误差(因为分子很容易变为零),我的应用程序仍将其视为非垃圾邮件!
这是我第一次遇到这样的问题。那么这个问题应该如何解决呢?
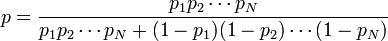
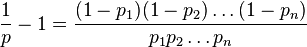



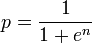
exp函数 http://www.codecogs.com/reference/c/math.h/exp.php 。即使用exp(eta)代替pow(2.71828182845905,eta)。 - Jacobp_i很小时,这仍会失去一些准确性;如果这对你的目的有影响,解决方法是将ln(1-p_i)替换为log1p(-p_i),这样就不会遇到相同的问题。(log1p是C标准库中未充分利用的宝石) - Stephen Canonp_i的二进制指数是-n,在计算log(1-p_i)时,您应该期望失去n-1位精度。因此,如果p_i是0.1(二进制指数:-3),则您将失去2位精度,而如果使用log1p(-p_i)可能会保留更多精度。显然,这并不太糟糕,但如果p_i比这小得多,则损失可能相当大。是否值得担心这种差异取决于p_i的分布情况。如果它们都很小且规模相似,则问题非常重要。如果它们具有极大的规模差异,则可能完全没有关系。 - Stephen Canonp_i很小时,log(p_i)项将支配log(1 - p_i)项,所以小项的精度损失对最终结果影响微乎其微。在更一般的情况下,如果您有一个涉及形式为log(1 + x)的数值敏感计算,应考虑用log1p(x)替换它。 - Stephen Canon