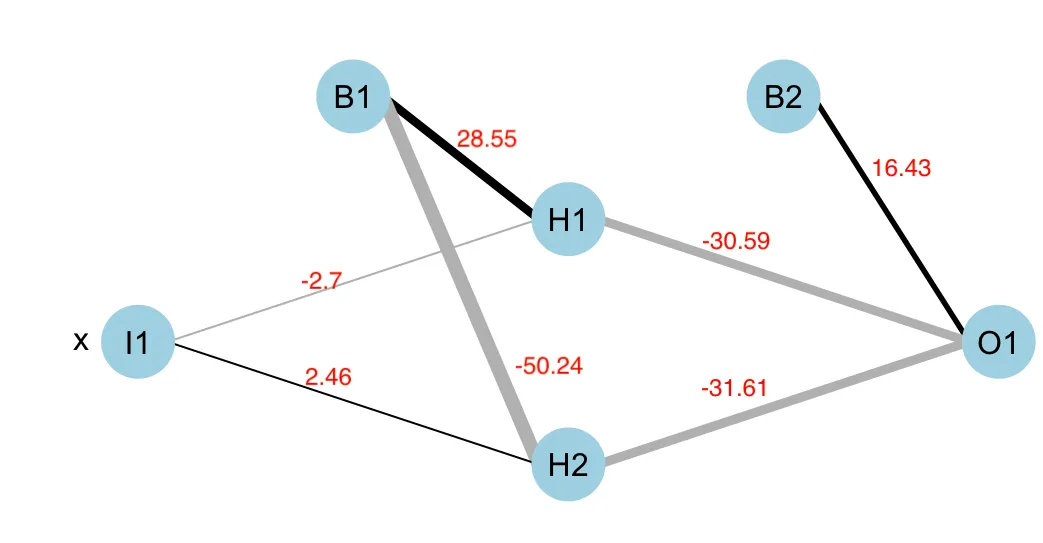
这个问题展示了对神经网络来说输入数据归一化的重要性。如果没有进行归一化,有时训练神经网络会很困难,因为优化可能会卡在某些局部最小值处。
我想从数据集的可视化开始。这个数据集是一维的,在使用标准归一化后,它看起来像下面这样。
X_original = np.concatenate([np.linspace(0, 10, 100), np.linspace(
11, 20, 100), np.linspace(21, 30, 100)])
X = (X_original - X_original.mean())/X_original.std()
y = np.concatenate(
[np.repeat(0, 100), np.repeat(1, 100), np.repeat(0, 100)])
plt.figure()
plt.scatter(X, np.zeros(X.shape[0]), c=y)
plt.show()
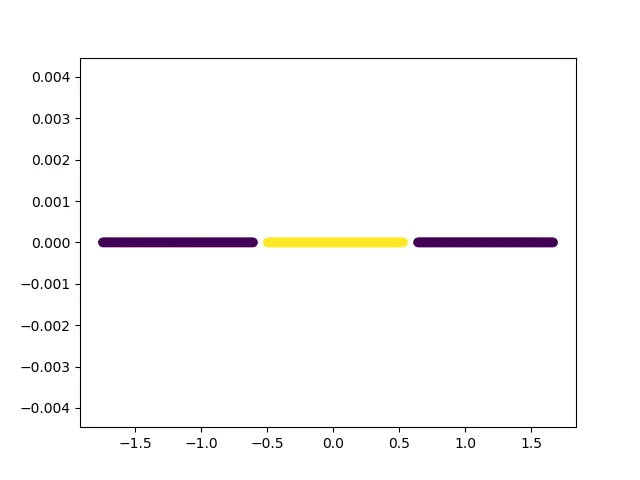 将这些数据点分成各自的类别的最佳方式是在输入空间上画两条线。由于输入空间为1D,分类边界只是1D点。
将这些数据点分成各自的类别的最佳方式是在输入空间上画两条线。由于输入空间为1D,分类边界只是1D点。
这意味着单层网络(例如逻辑回归)无法对此数据集进行分类。但是,一个带有两个层和非线性激活的神经网络应该能够对数据集进行分类。
现在,在进行规范化和以下训练脚本后,模型可以轻松学习分类点的方法。
model = Sequential()
model.add(Dense(2, activation='sigmoid'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adam(1e-1), metrics=['accuracy'])
model.fit(X, y, epochs=20)
Train on 300 samples
Epoch 1/20
300/300 [==============================] - 1s 2ms/sample - loss: 0.6455 - accuracy: 0.6467
Epoch 2/20
300/300 [==============================] - 0s 79us/sample - loss: 0.6493 - accuracy: 0.6667
Epoch 3/20
300/300 [==============================] - 0s 85us/sample - loss: 0.6397 - accuracy: 0.6667
Epoch 4/20
300/300 [==============================] - 0s 100us/sample - loss: 0.6362 - accuracy: 0.6667
Epoch 5/20
300/300 [==============================] - 0s 115us/sample - loss: 0.6342 - accuracy: 0.6667
Epoch 6/20
300/300 [==============================] - 0s 96us/sample - loss: 0.6317 - accuracy: 0.6667
Epoch 7/20
300/300 [==============================] - 0s 93us/sample - loss: 0.6110 - accuracy: 0.6667
Epoch 8/20
300/300 [==============================] - 0s 110us/sample - loss: 0.5746 - accuracy: 0.6667
Epoch 9/20
300/300 [==============================] - 0s 142us/sample - loss: 0.5103 - accuracy: 0.6900
Epoch 10/20
300/300 [==============================] - 0s 124us/sample - loss: 0.4207 - accuracy: 0.9367
Epoch 11/20
300/300 [==============================] - 0s 124us/sample - loss: 0.3283 - accuracy: 0.9833
Epoch 12/20
300/300 [==============================] - 0s 124us/sample - loss: 0.2553 - accuracy: 0.9800
Epoch 13/20
300/300 [==============================] - 0s 138us/sample - loss: 0.2030 - accuracy: 1.0000
Epoch 14/20
300/300 [==============================] - 0s 124us/sample - loss: 0.1624 - accuracy: 1.0000
Epoch 15/20
300/300 [==============================] - 0s 150us/sample - loss: 0.1375 - accuracy: 1.0000
Epoch 16/20
300/300 [==============================] - 0s 122us/sample - loss: 0.1161 - accuracy: 1.0000
Epoch 17/20
300/300 [==============================] - 0s 115us/sample - loss: 0.1025 - accuracy: 1.0000
Epoch 18/20
300/300 [==============================] - 0s 126us/sample - loss: 0.0893 - accuracy: 1.0000
Epoch 19/20
300/300 [==============================] - 0s 121us/sample - loss: 0.0804 - accuracy: 1.0000
Epoch 20/20
300/300 [==============================] - 0s 132us/sample - loss: 0.0720 - accuracy: 1.0000
由于该模型非常简单,学习率和优化器的选择会影响学习速度。使用SGD优化器和学习率为1e-1,与使用相同学习率的Adam优化器相比,模型的训练时间可能会更长。