我决定在Java中尝试一些关于神经网络的简单概念,并且在改编了一些我在论坛上找到的无用代码后,我成功地创建了一个非常简单的模型来模拟典型初学者的XOR运算:
public class MainApp {
public static void main (String [] args) {
Neuron xor = new Neuron(0.5f);
Neuron left = new Neuron(1.5f);
Neuron right = new Neuron(0.5f);
left.setWeight(-1.0f);
right.setWeight(1.0f);
xor.connect(left, right);
for (String val : args) {
Neuron op = new Neuron(0.0f);
op.setWeight(Boolean.parseBoolean(val));
left.connect(op);
right.connect(op);
}
xor.fire();
System.out.println("Result: " + xor.isFired());
}
}
public class Neuron {
private ArrayList inputs;
private float weight;
private float threshhold;
private boolean fired;
public Neuron (float t) {
threshhold = t;
fired = false;
inputs = new ArrayList();
}
public void connect (Neuron ... ns) {
for (Neuron n : ns) inputs.add(n);
}
public void setWeight (float newWeight) {
weight = newWeight;
}
public void setWeight (boolean newWeight) {
weight = newWeight ? 1.0f : 0.0f;
}
public float getWeight () {
return weight;
}
public float fire () {
if (inputs.size() > 0) {
float totalWeight = 0.0f;
for (Neuron n : inputs) {
n.fire();
totalWeight += (n.isFired()) ? n.getWeight() : 0.0f;
}
fired = totalWeight > threshhold;
return totalWeight;
}
else if (weight != 0.0f) {
fired = weight > threshhold;
return weight;
}
else {
return 0.0f;
}
}
public boolean isFired () {
return fired;
}
}
在我的主类中,我已经按照Jeff Heaton的图表创建了简单的模拟:
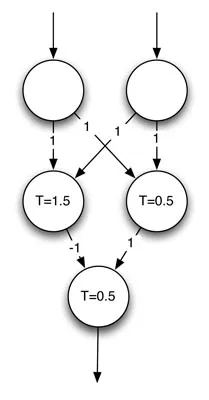 然而,我想确保神经元类的实现是正确的。我已经测试了所有可能的输入([true true],[true false],[false true],[false false]),并且它们都通过了我的手动验证。此外,由于这个程序接受输入作为参数,对于像[true false false],[true true false]等输入,它似乎也通过了手动验证。
然而,我想确保神经元类的实现是正确的。我已经测试了所有可能的输入([true true],[true false],[false true],[false false]),并且它们都通过了我的手动验证。此外,由于这个程序接受输入作为参数,对于像[true false false],[true true false]等输入,它似乎也通过了手动验证。但从概念上讲,这种实现是否正确?或者在我开始进一步开发和研究这个主题之前,我应该如何改进它?
谢谢!