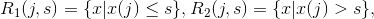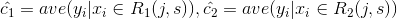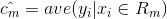我有一个关于使用连续变量的决策树的问题。
我听说当输出变量是连续的而输入变量是分类的时候,分割标准是降低方差之类的东西。但如果输入变量是连续的,我不知道它是如何工作的。
对于以下两种情况,我们如何获得像基尼指数或信息增益这样的分割标准?
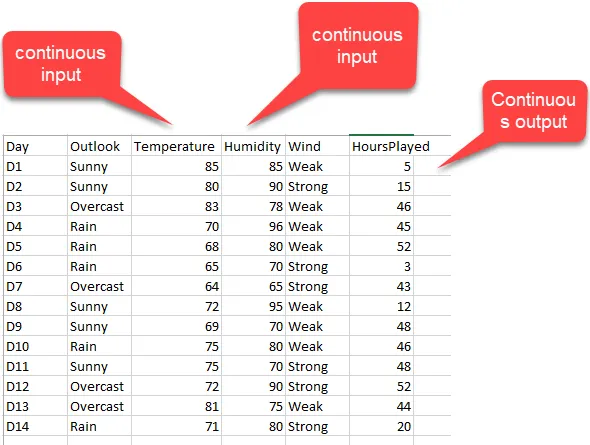
1. 输入变量:连续 / 输出变量:分类 2. 输入变量:连续 / 输出变量:连续
当我在R中使用rpart时,无论输入变量和输出变量是什么,它都能很好地工作,但我不知道算法的详细信息。
我听说当输出变量是连续的而输入变量是分类的时候,分割标准是降低方差之类的东西。但如果输入变量是连续的,我不知道它是如何工作的。
对于以下两种情况,我们如何获得像基尼指数或信息增益这样的分割标准?
1. 输入变量:连续 / 输出变量:分类 2. 输入变量:连续 / 输出变量:连续
当我在R中使用rpart时,无论输入变量和输出变量是什么,它都能很好地工作,但我不知道算法的详细信息。