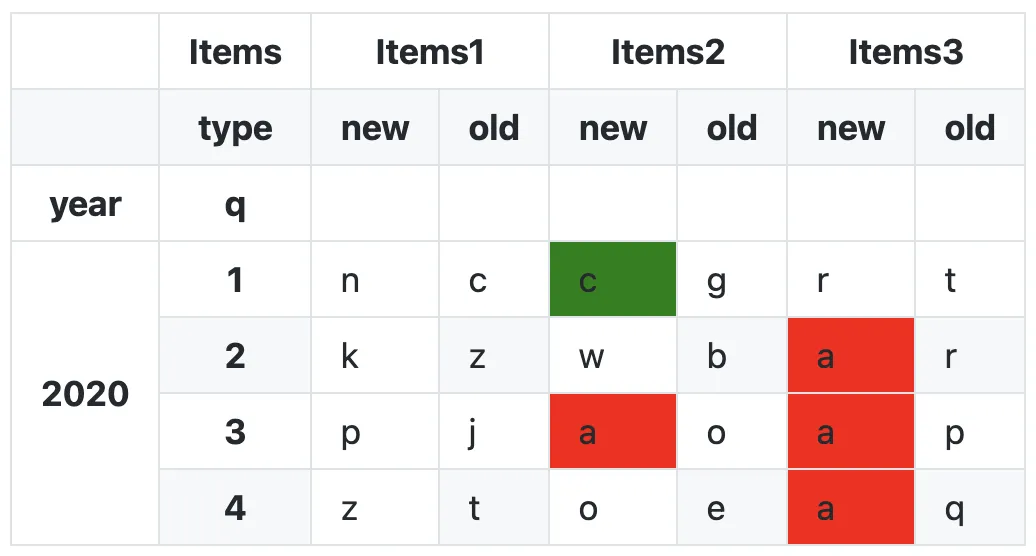
我有一个多级索引的数据框,我提供了最小可复现样例。
import pandas as pd
import numpy as np
import string
index = pd.MultiIndex.from_product(
([2020], [1, 2, 3, 4]), names=['year', 'q']
)
columns = pd.MultiIndex.from_product(
(['Items1', 'Items2', 'Items3'], ['new', 'old']),
names=['Items', 'type']
)
data = np.random.seed(123)
data = list(np.random.choice(list(string.ascii_lowercase), (4,6)))
Ldata = pd.DataFrame(data, index=index, columns=columns)
Ldata
我想在数据框中标记特定的值,我是这样做的。但是我不知道在哪里放置多级索引level=1。我尝试了一下,但出现了错误,请问我应该在哪里添加level?
def highlight_cells(x):
c = 'background-color: white'
c1 = 'background-color: red'
c2 = 'background-color: blue'
c3 = 'background-color: green'
k1 = Ldata['new'].str.contains("a", na=False)
k2 = Ldata['new'].str.contains("b", na=False)
k3 = Ldata['new'].str.contains("c", na=False)
colordata = pd.DataFrame(c, index=x.index, columns=x.columns)
colordata.loc[k1, 'new'] = c1
colordata.loc[k2, 'new'] = c2
colordata.loc[k3, 'new'] = c3
return colordata
end = Ldata.style.apply(highlight_cells,axis=None)
end
提前致谢!
Ldata.loc[:, pd.IndexSlice[:, 'new']]将返回一个 DataFrame。而且没有DataFrame.str.contains方法。 - Henry Ecker.apply来执行它。 - shadowtalker.apply和一个小的辅助函数。当然,你不需要这个辅助函数,你可以直接复制粘贴。 - shadowtalkerk1、k2和k3是数据框,但你正在将它们传递给loc的索引切片。 - Henry Ecker