以下代码生成名为
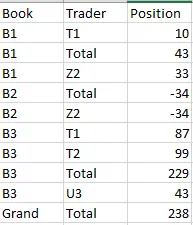
的表格如图所示:
out的pandas表格。import pandas as pd
import numpy as np
df = pd.DataFrame({'Book': ['B1', 'B1', 'B2', 'B3', 'B3', 'B3'],
'Trader': ['T1', 'Z2', 'Z2', 'T1', 'U3', 'T2'],
'Position':[10, 33, -34, 87, 43, 99]})
df = df[['Book', 'Trader', 'Position']]
table = pd.pivot_table(df, index=['Book', 'Trader'], values=['Position'], aggfunc=np.sum)
print(table)
tab_tots = table.groupby(level='Book').sum()
tab_tots.index = [tab_tots.index, ['Total'] * len(tab_tots)]
print(tab_tots)
out = pd.concat(
[table, tab_tots]
).sort_index().append(
table.sum().rename(('Grand', 'Total'))
)
out但我希望它看起来像这样: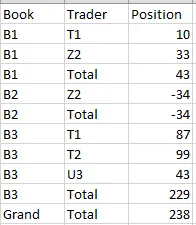
请注意,第二个表格总是将“Total”放在底部。 因此,基本上我仍然想按字母顺序排序,但我想始终将“Total”放在最后。 有人能提供一些代码调整以获得我想要的输出吗?