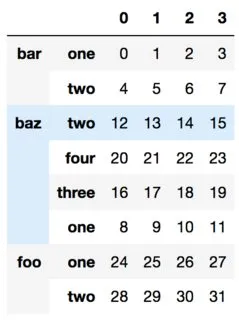
我有一个多层次的数据框,名为df:
arrays = [['bar', 'bar', 'baz', 'baz', 'baz', 'baz', 'foo', 'foo'],
['one', 'two', 'one', 'two', 'three', 'four', 'one', 'two']]
df = pd.DataFrame(np.ones([8, 4]), index=arrays)
这看起来像:
0 1 2 3
bar one 1.0 1.0 1.0 1.0
two 1.0 1.0 1.0 1.0
baz one 1.0 1.0 1.0 1.0
two 1.0 1.0 1.0 1.0
three 1.0 1.0 1.0 1.0
four 1.0 1.0 1.0 1.0
foo one 1.0 1.0 1.0 1.0
two 1.0 1.0 1.0 1.0
我现在需要将“baz”子级别按照新顺序排序,以创建类似于“df_end”的东西:
arrays_end = [['bar', 'bar', 'baz', 'baz', 'baz', 'baz', 'foo', 'foo'],
['one', 'two', 'two', 'four', 'three', 'one', 'one', 'two']]
df_end = pd.DataFrame(np.ones([8, 4]), index=arrays_end)
看起来像这样:
0 1 2 3
bar one 1.0 1.0 1.0 1.0
two 1.0 1.0 1.0 1.0
baz two 1.0 1.0 1.0 1.0
four 1.0 1.0 1.0 1.0
three 1.0 1.0 1.0 1.0
one 1.0 1.0 1.0 1.0
foo one 1.0 1.0 1.0 1.0
two 1.0 1.0 1.0 1.0
我想,我可能可以重新索引 baz 行:
new_index = ['two','four','three','one']
df.loc['baz'].reindex(new_index)
这将导致:
0 1 2 3
two 1.0 1.0 1.0 1.0
four 1.0 1.0 1.0 1.0
three 1.0 1.0 1.0 1.0
one 1.0 1.0 1.0 1.0
...并将这些值插入回原始的DataFrame中:
df.loc['baz'] = df.loc['baz'].reindex(new_index)
但结果是:
0 1 2 3
bar one 1.0 1.0 1.0 1.0
two 1.0 1.0 1.0 1.0
baz one NaN NaN NaN NaN
two NaN NaN NaN NaN
three NaN NaN NaN NaN
four NaN NaN NaN NaN
foo one 1.0 1.0 1.0 1.0
two 1.0 1.0 1.0 1.0
但这不是我要找的!所以我的问题是如何使用new_index来重新排序baz索引中的行。任何建议都将不胜感激。