我有一个数据帧,已经按用户和时间排序
df = pd.DataFrame({'user' : ['A', 'A', 'A', 'B', 'B', 'B','B'],
'location' : ['house','house','gym','gym','shop','gym','gym'],
'duration':[10,5,5,4,10,4,6]})
duration location user
0 10 house A
1 5 house A
2 5 gym A
3 4 gym B
4 10 shop B
5 4 gym B
6 6 gym B
我只想在给定用户的相邻行中,“位置”字段相同时执行sum()。因此,不仅仅是df.groupby(['id','location']).duration.sum()。期望的输出如下所示。此外,顺序很重要。
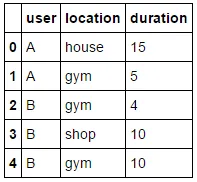
duration location user
15 house A
5 gym A
4 gym B
10 shop B
10 gym B
谢谢!
df.location.shift()时,它将所有值向下移动一个级别。我们这样做是为了将我们当前的值与之进行比较的估计。每当df.location和df.location.shift()下的值匹配时,(df.location != df.location.shift())返回False。因此,只要相同的值重复出现N次,我们就会得到(N-1)个False返回。 - Nickil Mavelicumsum设置为False,这将计算为0,无论有多少个这样的False值存在,它们仍将导致1。(1+0+0+...N次)。 - Nickil Maveli