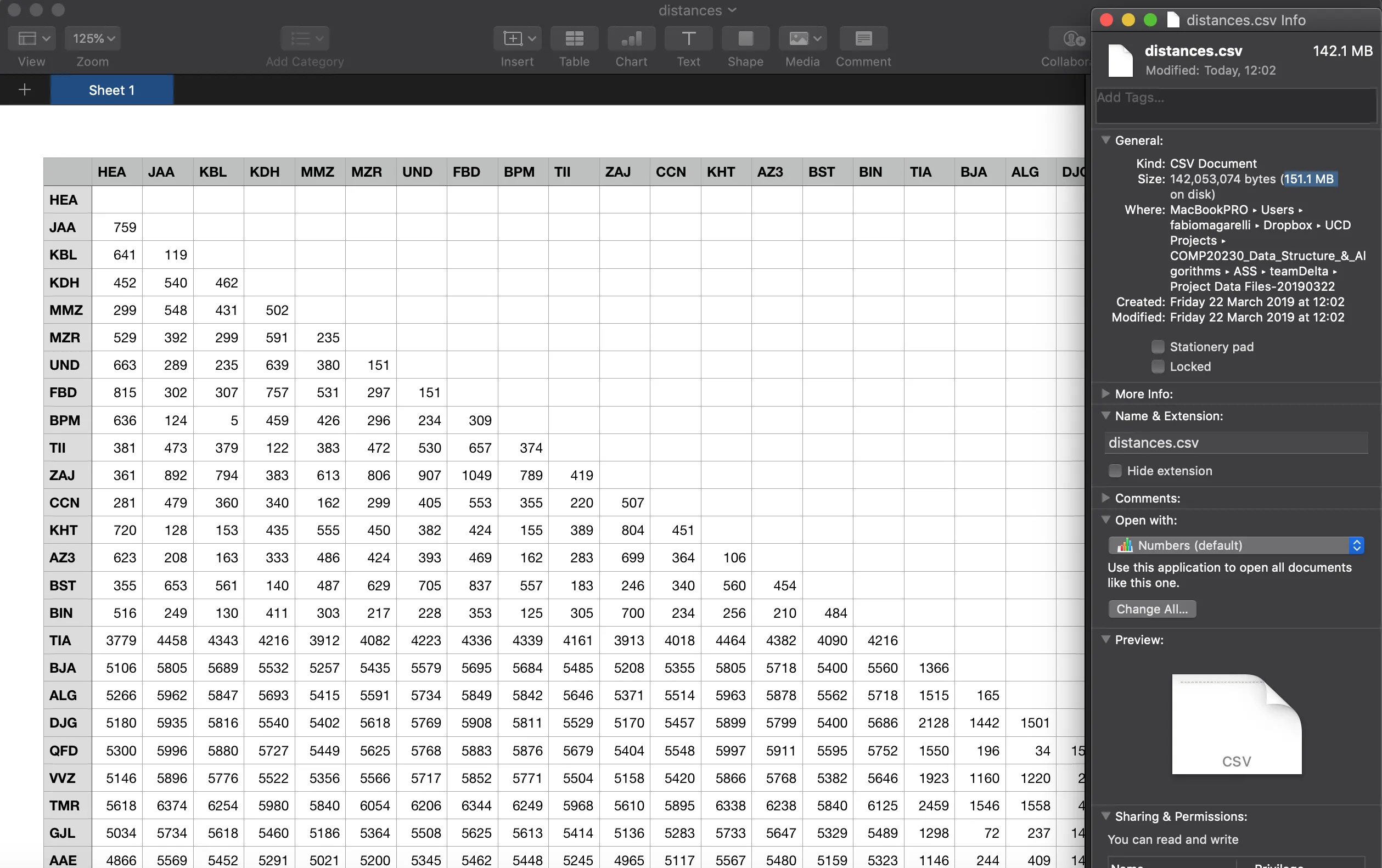
我需要制作一个包含世界各地机场距离的CSV文件来完成我的大学作业……问题是我的CSV文件大小为151MB,我希望尽可能地减小它的大小。
这是我的CSV文件:
这是我的代码:
# drop all features we don't need
for attribute in df:
if attribute not in ('NAME', 'COUNTRY', 'IATA', 'LAT', 'LNG'):
df = df.drop(attribute, axis=1)
# create a dictionary of airports, each airport has the following structure:
# IATA : (NAME, COUNTRY, LAT, LNG)
airport_dict = {}
for airport in df.itertuples():
airport_dict[airport[3]] = (airport[1], airport[2], airport[4], airport[5])
# From tutorial 4 soulution:
airportcodes=list(airport_dict)
airportdists=pd.DataFrame()
for i, airport_code1 in enumerate(airportcodes):
airport1 = airport_dict[airport_code1]
dists=[]
for j, airport_code2 in enumerate(airportcodes):
if j > i:
airport2 = airport_dict[airport_code2]
dists.append(distanceBetweenAirports(airport1[2],airport1[3],airport2[2],airport2[3]))
else:
# little edit: no need to calculate the distance twice, all duplicates are set to 0 distance
dists.append(0)
airportdists[i]=dists
airportdists.columns=airportcodes
airportdists.index=airportcodes
# set all 0 distance values to NaN
airportdists = airportdists.replace(0, np.nan)
airportdists.to_csv(r'../Project Data Files-20190322/distances.csv')
我也尝试在保存之前重新索引它:
# remove all NaN values
airportdists = airportdists.stack().reset_index()
airportdists.columns = ['airport1','airport2','distance']
但是结果是一个有3列和1700万行的数据框,磁盘大小为419Mb...并没有太大的改进...
你能帮我缩小csv文件的大小吗?谢谢!