如果我有一个数据框 df,其中包括列 x,并且想要根据 x 的值创建列 y,可以使用以下伪代码:
if df['x'] < -2 then df['y'] = 1
else if df['x'] > 2 then df['y'] = -1
else df['y'] = 0
np.where是最好的方法,但不确定如何编写正确的代码。如果我有一个数据框 df,其中包括列 x,并且想要根据 x 的值创建列 y,可以使用以下伪代码:
if df['x'] < -2 then df['y'] = 1
else if df['x'] > 2 then df['y'] = -1
else df['y'] = 0
np.where是最好的方法,但不确定如何编写正确的代码。一种简单的方法是先分配默认值,然后执行 2 次 loc 调用:
In [66]:
df = pd.DataFrame({'x':[0,-3,5,-1,1]})
df
Out[66]:
x
0 0
1 -3
2 5
3 -1
4 1
In [69]:
df['y'] = 0
df.loc[df['x'] < -2, 'y'] = 1
df.loc[df['x'] > 2, 'y'] = -1
df
Out[69]:
x y
0 0 0
1 -3 1
2 5 -1
3 -1 0
4 1 0
如果你想使用np.where,那么你可以通过嵌套的方式使用np.where:
In [77]:
df['y'] = np.where(df['x'] < -2 , 1, np.where(df['x'] > 2, -1, 0))
df
Out[77]:
x y
0 0 0
1 -3 1
2 5 -1
3 -1 0
4 1 0
因此,我们将第一个条件定义为x小于-2时返回1,然后我们有另一个np.where测试另一个条件,即x大于2时返回-1,否则返回0。
时间
In [79]:
%timeit df['y'] = np.where(df['x'] < -2 , 1, np.where(df['x'] > 2, -1, 0))
1000 loops, best of 3: 1.79 ms per loop
In [81]:
%%timeit
df['y'] = 0
df.loc[df['x'] < -2, 'y'] = 1
df.loc[df['x'] > 2, 'y'] = -1
100 loops, best of 3: 3.27 ms per loop
因此,针对这个示例数据集,np.where 方法的速度是两倍于其他方法。
np.select处理多个条件
np.select(condlist, choicelist, default=0)
- 根据
condlist中的相应条件返回choicelist中的元素。- 当所有条件都为
False时,将使用default元素。
condlist = [
df['x'] < -2,
df['x'] > 2,
]
choicelist = [
1,
-1,
]
df['y'] = np.select(condlist, choicelist, default=0)
np.select 比嵌套的 np.where 更易读,并且速度相同:
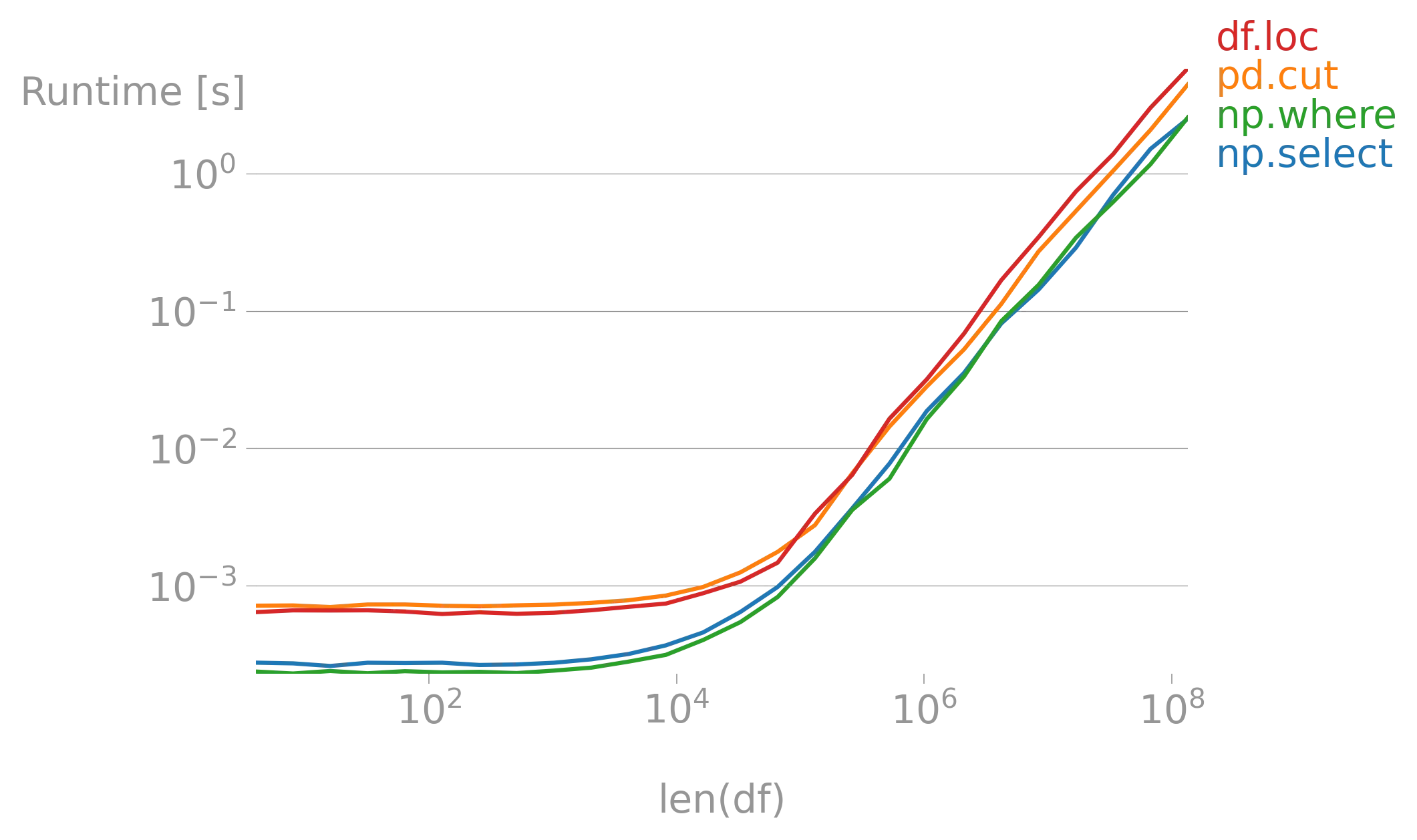
df = pd.DataFrame({'x': np.random.randint(-5, 5, size=n)})
pd.cut 的案例,你可以定义一个范围,根据这个 范围 来为其赋予相应的 标签:df['y'] = pd.cut(df['x'], [-np.inf, -2, 2, np.inf], labels=[1, 0, -1], right=False)
输出
x y
0 0 0
1 -3 1
2 5 -1
3 -1 0
4 1 0
df.loc[df['c1'] == 'Value', 'c2'] = 10
您可以使用索引和 2 个 loc 调用轻松实现它:
df = pd.DataFrame({'x':[0,-3,5,-1,1]})
df
x
0 0
1 -3
2 5
3 -1
4 1
df['y'] = 0
idx_1 = df.loc[df['x'] < -2, 'y'].index
idx_2 = df.loc[df['x'] > 2, 'y'].index
df.loc[idx_1, 'y'] = 1
df.loc[idx_2, 'y'] = -1
df
x y
0 0 0
1 -3 1
2 5 -1
3 -1 0
4 1 0
.loc 调用,然后需要进行 .index 处理。 - ggorlen
np.where处理两个选择,使用np.select处理多个选择。 - Paul Rougieux