我希望在不使用缓慢的for循环的情况下,能够在列condrolmax(基于列close)中实现以下结果(条件滚动/累积最大值)。
创建此数据帧的代码:
Index close bool condrolmax
0 1 True 1
1 3 True 3
2 2 True 3
3 5 True 5
4 3 False 5
5 3 True 3 --> rolling/accumulative maximum reset (False cond above)
6 4 True 4
7 5 False 4
8 7 False 4
9 5 True 5 --> rolling/accumulative maximum reset (False cond above)
10 7 False 5
11 8 False 5
12 6 True 6 --> rolling/accumulative maximum reset (False cond above)
13 8 True 8
14 5 False 8
15 5 True 5 --> rolling/accumulative maximum reset (False cond above)
16 7 True 7
17 15 True 15
18 16 True 16
创建此数据帧的代码:
# initialise data of lists.
data = {'close':[1,3,2,5,3,3,4,5,7,5,7,8,6,8,5,5,7,15,16],
'bool':[True, True, True, True, False, True, True, False, False, True, False,
False, True, True, False, True, True, True, True],
'condrolmax': [1,3,3,5,5,3,4,4,4,5,5,5,6,8,8,5,7,15,16]}
# Create DataFrame
df = pd.DataFrame(data)
我相信可以对其进行向量化处理(一行代码解决)。有什么建议吗?
再次感谢!
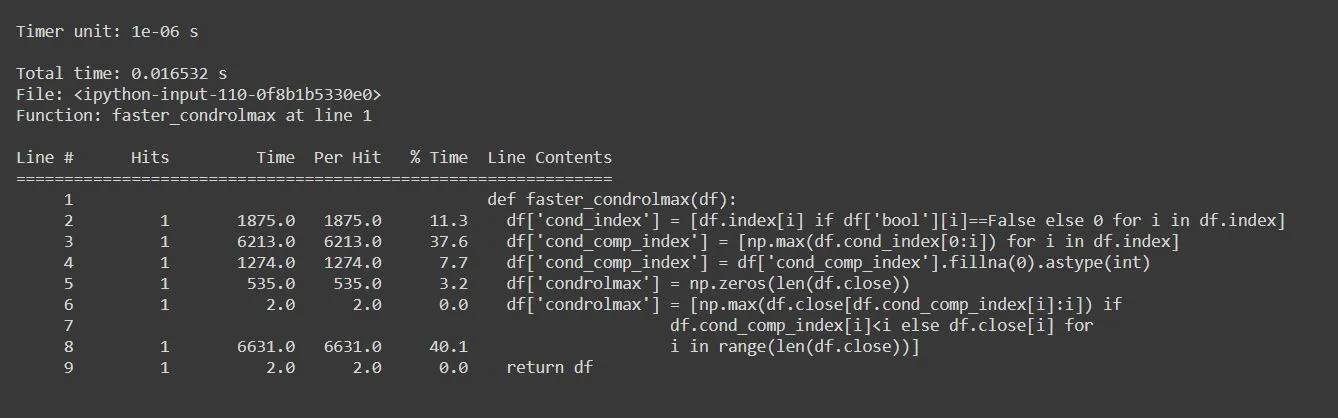{kind=link}
{kind=link}
{kind=link}
rolling()函数没有提及窗口大小(如果适用),实际上窗口大小可以根据列bool的模式而变化。因此,如果要使用滚动函数,最好使用expanding()而不是rolling()。在这种情况下,在组内使用cummax()会更直接。这就是我们选择cummax()而不是rolling.max()的原因。 - SeaBean