我有以下数据:
dput(dat)
structure(list(Band = c(1930, 1930, 1930, 1930, 1930, 1930, 1930,
1930, 1930, 1930, 1930, 1930, 1930, 1930, 1930, 1930, 1930, 1930
), Reflectance = c(25.296494, 21.954657, 18.981184, 15.984661,
14.381341, 12.485372, 10.592539, 8.51772, 7.601568, 7.075429,
6.205453, 5.36646, 4.853167, 4.21576, 3.979639, 3.504217, 3.313851,
2.288752), Number.of.Sprays = c(0, 1, 2, 3, 5, 6, 7, 9, 10, 11,
14, 17, 19, 21, 27, 30, 36, 49), Legend = structure(c(4L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 5L
), .Label = c("1 x spray between each measurement", "2 x spray between each measurement",
"3 x spray between each measurement", "Dry soil", "Wet soil"), class = "factor")), .Names =c("Band",
"Reflectance", "Number.of.Sprays", "Legend"), row.names = c(NA,
-18L), class = "data.frame")
这导致以下图表的生成:
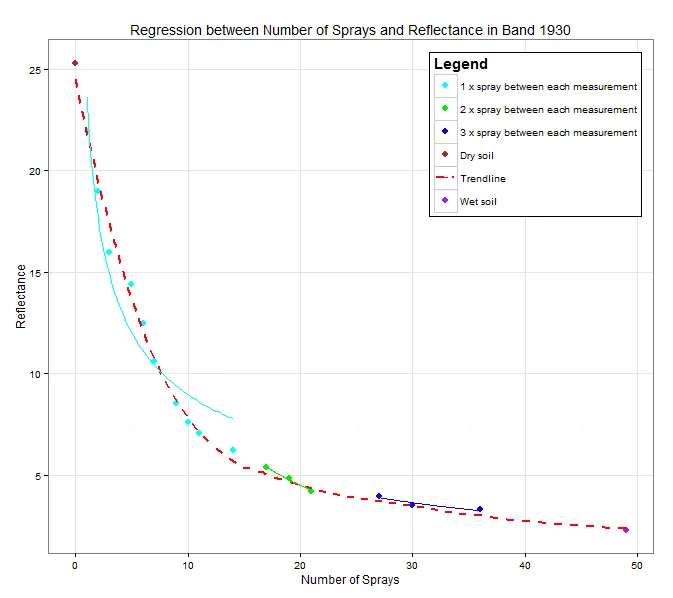
g <- ggplot(dat, aes(Number.of.Sprays, Reflectance, colour = Legend)) +
geom_point (size = 3) +
geom_smooth (aes(group = 1, colour = "Trendline"), method = "loess", size = 1, linetype = "dashed", se = FALSE) +
stat_smooth(method = "nls", formula = "y ~ a*x^b", start = list(a = 1, b = 1), se = FALSE)+
theme_bw (base_family = "Times") +
labs (title = "Regression between Number of Sprays and Reflectance in Band 1930") +
xlab ("Number of Sprays") +
guides (colour = guide_legend (override.aes = list(linetype = c(rep("blank", 4), "dashed", "blank"), shape = c(rep(16, 4), NA, 16)))) +
scale_colour_manual (values = c("cyan", "green2", "blue", "brown", "red", "purple")) +
theme (legend.title = element_text (size = 15), legend.justification = c(1,1),legend.position = c(1,1), legend.background = element_rect (colour = "black", fill = "white"))
注意:我并不完全理解我的stat_smooth线以及其中的起始特征,只是从另一个帖子中适应过来的。
现在我的问题和目标:
是否有一个包/函数可以提供更准确的估计哪种线性函数最适合点?还是我需要尝试各种功能公式并查看哪个最适合?基于
method="loess"的“趋势线”看起来非常好,但我不知道它是如何计算的。为什么通过
stat_smooth()应用的线取决于数据中的因子级别,而不只是依赖于所有数据点?为什么“趋势线”的虚线图例图标看起来那么糟糕? (我该怎样改变这个?)
如果我随时有一个适合的非线性回归线,在上面如何计算R²?(
summary(lm())只对线性关系进行计算。)是否有可能根据非线性回归线的公式计算R²?
我知道这是很多问题,也许其中一些与统计学相关而不是直接与R相关。如果有什么不对,请编辑这个问题。
感谢您的所有帮助, Patrick
- 你传递给
- 因为你映射了
- 你所说的“坏”是什么意思?
- https://stat.ethz.ch/pipermail/r-help/2002-July/023461.html
- Rolandnls的函数应该基于数据背后的科学选择。loess是一个平滑器,即非参数拟合。colour = Legend。- 好的,所以没有可以为我完成这个任务的“函数”或工具?例如,对于Excel,您可以使用http://www.nutonian.com/products/eureqa/。
- 那很有道理。如果我把它删除,我的代码就不能正常工作了,我会收到一个奇怪的错误消息 =/
- 我的意思是图标看起来厚度不一致,有一条粗线和小点。更希望/期望作为符号的是2个相等的破折号?
- 谢谢!
- pat-s