我有一个Pandas数据框(countries),需要获取特定的索引值。(比如索引2 => 我需要日本)
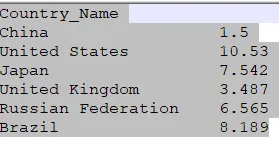
我使用了iloc,但是我得到的数据是 (7.542)
return countries.iloc[2]
7.542
我有一个Pandas数据框(countries),需要获取特定的索引值。(比如索引2 => 我需要日本)
我使用了iloc,但是我得到的数据是 (7.542)
return countries.iloc[2]
7.542
直接调用索引
return countries.index[2]
但是你在这里发布的内容看起来更像是一个pandas数据帧而不是一个系列 - 如果是这样,请执行
countries['Country_Name'].iloc[2]
countries['Country_Name'].index[2]。 - Kaleb Coberly这正是我想问的问题!阅读其他回答帮助我找到了答案。
正如其他回答者所提到的,表格的结构看起来像是一个包含两列的数据框,一列为“Country_Names”,另一列未命名的值,此时索引将默认为[0,1...n]。
但是,你的示例代码return countries.iloc[2] #7.542表明你有一个系列,因为它只返回一个标量值,而不是一个带有索引和数据类型的键值对(见下文)。
因此,让我们假设你有一个数据框,就像你说的那样,有一个值列和“Country_Names”作为索引。我将为值列添加一个名称并添加第二个值列:
countries = pd.DataFrame({'Country_Names': ['China', 'United States', 'Japan', 'United Kingdom', 'Russian Federation', 'Brazil'],
'Values1': [1.5, 10.53, 7.542, 3.487, 6.565, 8.189],
'Values2': [1,2,3,4,5,6]}).set_index('Country_Names')
print(countries)
# Values1 Values2
# Country_Names
# China 1.500 1
# United States 10.530 2
# Japan 7.542 3
# United Kingdom 3.487 4
# Russian Federation 6.565 5
# Brazil 8.189 6
countries.index[2] #The 3rd index of the dataframe:
# 'Japan'
countries['Values1'].index[2] #The 3rd index of the 1st column (which is a series)
# 'Japan'
countries.iloc[2] #The 3rd row of the dataframe.
# Values1 7.542
# Values2 3.000
# Name: Japan, dtype: float64
countries['Values1'].iloc[2] #The 3rd row of the 1st column (which is a series)
# 7.542
现在,如果你实际上只是处理一个系列(就像你的代码所示),而不是一个数据框,那么它看起来会像这样:
Country_Names = ['China', 'United States', 'Japan', 'United Kingdom', 'Russian Federation', 'Brazil']
countries = pd.Series([1.5, 10.53, 7.542, 3.487, 6.565, 8.189], index=Country_Names)
countries
# China 1.500
# United States 10.530
# Japan 7.542
# United Kingdom 3.487
# Russian Federation 6.565
# Brazil 8.189
# dtype: float64
countries.index[2]
# 'Japan'
countries.iloc[2]
# 7.542
我不确定如何构建一个数据对象,可以按照你在问题中提到的表格打印出来。
编辑
这是如何做的。创建一个具有名称的索引,并将该索引赋给一个系列:
Country_Names = pd.Index(['China', 'United States', 'Japan', 'United Kingdom', 'Russian Federation', 'Brazil'],
name='Country_Names')
countries_s = pd.Series([1.5, 10.53, 7.542, 3.487, 6.565, 8.189], index=Country_Names)
countries_s
# Country_Names
# China 1.500
# United States 10.530
# Japan 7.542
# United Kingdom 3.487
# Russian Federation 6.565
# Brazil 8.189
# dtype: float64
这基本上证实了您正在使用系列。无论如何,我不确定是否可能拥有未命名的数据框。
countries['Country_Name'].iloc[2]