我发现memory-views很方便和快速,因此在Cython中尽量避免创建NumPy数组,并使用给定数组的视图进行操作。然而,有时候不得不创建新的数组而不是修改现有数组。在高层函数中这并不明显,但在经常调用的子程序中就会有所体现。请考虑以下函数:
#@cython.profile(False)
@cython.boundscheck(False)
@cython.wraparound(False)
@cython.nonecheck(False)
cdef double [:] vec_eq(double [:] v1, int [:] v2, int cond):
''' Function output corresponds to v1[v2 == cond]'''
cdef unsigned int n = v1.shape[0]
cdef unsigned int n_ = 0
# Size of array to create
cdef size_t i
for i in range(n):
if v2[i] == cond:
n_ += 1
# Create array for selection
cdef double [:] s = np.empty(n_, dtype=np_float) # Slow line
# Copy selection to new array
n_ = 0
for i in range(n):
if v2[i] == cond:
s[n_] = v1[i]
n_ += 1
return s
性能分析告诉我,这里有一些可以提升的速度。
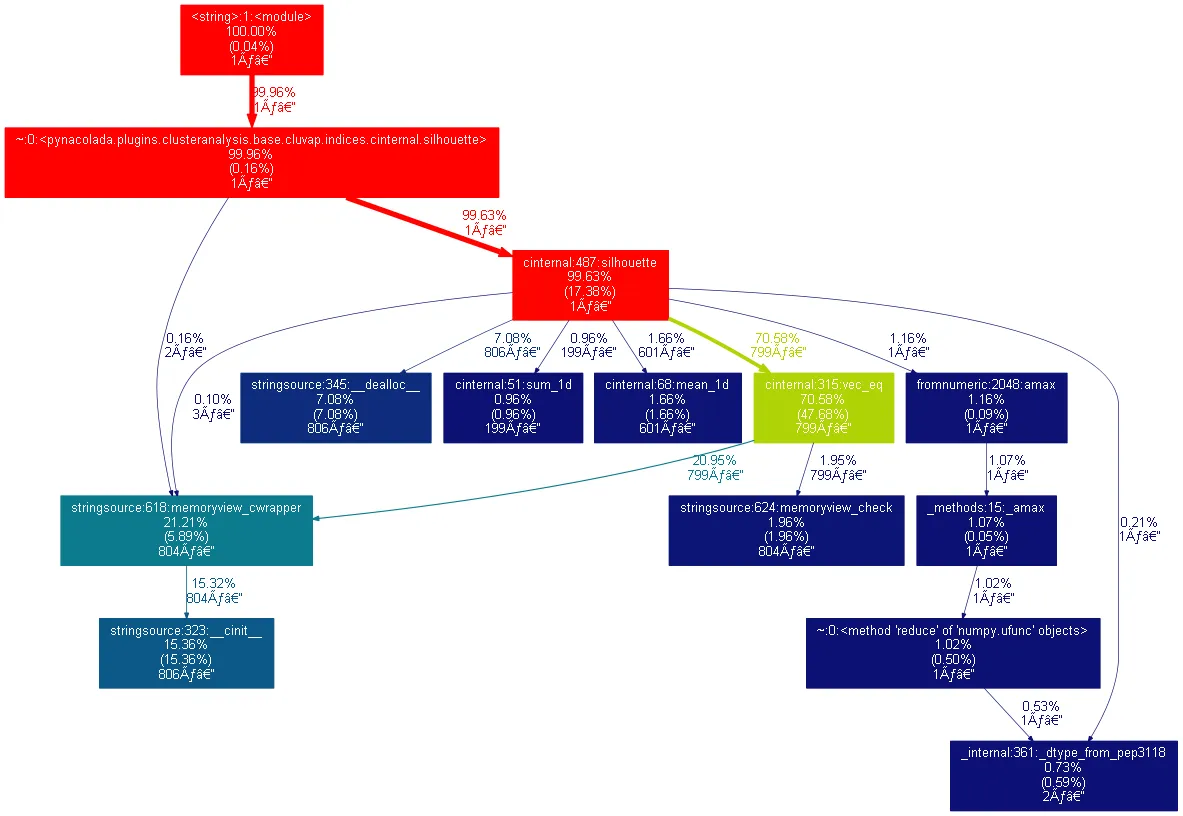
我可以尝试适应函数,因为有时候例如需要计算该向量的平均值,有时候需要求和。所以我可以重写它,以便进行求和或取平均值。但是,是否有一种方法可以"直接创建内存视图并动态定义大小,并带有非常小的开销"?比如,首先使用malloc等创建一个C缓冲区,然后在函数结束时将缓冲区转换为视图,传递指针和步长等。
编辑1:
也许对于简单的情况,像这样调整函数是可行的方法。我只添加了一个参数来实现求和/取平均值。这样我就不必创建数组,并且可以在易于处理的内部函数malloc中轻松处理。这样做不会更快,对吗?
# ...
cdef double vec_eq(double [:] v1, int [:] v2, int cond, opt=0):
# additional option argument
''' Function output corresponds to v1[v2 == cond].sum() / .mean()'''
cdef unsigned int n = v1.shape[0]
cdef int n_ = 0
# Size of array to create
cdef Py_ssize_t i
for i in prange(n, nogil=True):
if v2[i] == cond:
n_ += 1
# Create array for selection
cdef double s = 0
cdef double * v3 = <double *> malloc(sizeof(double) * n_)
if v3 == NULL:
abort()
# Copy selection to new array
n_ = 0
for i in range(n):
if v2[i] == cond:
v3[n_] = v1[i]
n_ += 1
# Do further computation here, according to option
# Option 0 for the sum
if opt == 0:
for i in prange(n_, nogil=True):
s += v3[i]
free(v3)
return s
# Option 1 for the mean
else:
for i in prange(n_, nogil=True):
s += v3[i]
free(v3)
return s / n_
# Since in the end there is always only a single double value,
# the memory can be freed right here
callback_memory_free实际上是cython.view.array的一个属性,而不是视图的属性。 - cfh