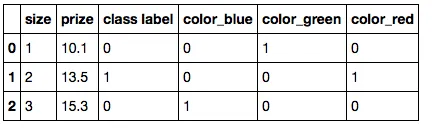
你是指"独热"编码吗?
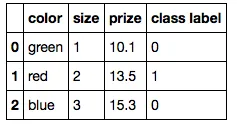
假设你有以下数据集:
import pandas as pd
df = pd.DataFrame([
['green', 1, 10.1, 0],
['red', 2, 13.5, 1],
['blue', 3, 15.3, 0]])
df.columns = ['color', 'size', 'prize', 'class label']
df
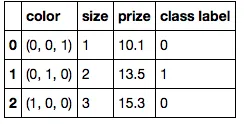
现在,你有多种选择...
A) 繁琐的方法
color_mapping = {
'green': (0,0,1),
'red': (0,1,0),
'blue': (1,0,0)}
df['color'] = df['color'].map(color_mapping)
df
import numpy as np
y = df['class label'].values
X = df.iloc[:, :-1].values
X = np.apply_along_axis(func1d= lambda x: np.array(list(x[0]) + list(x[1:])), axis=1, arr=X)
print('Class labels:', y)
print('\nFeatures:\n', X)
生成:
Class labels: [0 1 0]
Features:
[[ 0. 0. 1. 1. 10.1]
[ 0. 1. 0. 2. 13.5]
[ 1. 0. 0. 3. 15.3]]
B) Scikit-learn的DictVectorizer
from sklearn.feature_extraction import DictVectorizer
dvec = DictVectorizer(sparse=False)
X = dvec.fit_transform(df.transpose().to_dict().values())
X
产出:
array([[ 0. , 0. , 1. , 0. , 10.1, 1. ],
[ 1. , 0. , 0. , 1. , 13.5, 2. ],
[ 0. , 1. , 0. , 0. , 15.3, 3. ]])
C) Pandas的get_dummies
pd.get_dummies(df)