我有一些数据列表,表示对Likert问题的回答,其中使用了从1(非常不满意)到5(非常满意)的评分。 我想创建一个页面,显示这些列表作为倾斜的堆积水平条形图。 回答列表的大小可以不同(例如,当某人选择退出回答特定问题时)。以下是数据的最小示例:
likert1 = [1.0, 2.0, 1.0, 2.0, 1.0, 3.0, 3.0, 4.0, 4.0, 1.0, 1.0]
likert2 = [5.0, 4.0, 5.0, 4.0, 5.0, 3.0]
我希望能够使用类似下面这样的东西来绘制它:
plot_many_likerts(likert1, likert2)
目前,我编写了一个函数来遍历列表,并在matplotlib中的共享图形上绘制每个子图:
def plot_many_likerts(*lsts):
#get the figure and the list of axes for this plot
fig, axlst = plt.subplots(len(lsts), sharex=True)
for i in range(len(lsts)):
likert_horizontal_bar_list(lsts[i], axlst[i], xaxis=[1.0, 2.0, 3.0, 4.0, 5.0])
axlst[i].axis('off')
fig.show()
def likert_horizontal_bar_list(lst, ax, xaxis):
cnt = Counter(lst)
#del (cnt[None])
i = 0
colour_float = 0.00001
previous_right = 0
for key in sorted(xaxis):
ax.barh(bottom=0, width=cnt[key], height=0.4, left=previous_right, color=plt.cm.jet(colour_float),label=str(key))
i += 1
previous_right = previous_right + cnt[key]
colour_float = float(i) / float(len(xaxis))
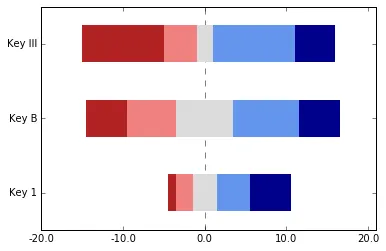
这个方法效果还不错,能够创建所有具有相同代表尺寸(例如宽度共享公共轴缩放)的堆叠条形图。以下是屏幕截图:
目前的成果 http://s7.postimg.org/vh0j816gn/figure_1.jpg
我希望这两个图表都以数据集模态值的中点为中心(数据集将具有相同的范围)。 例如:
我想要看到的内容 http://s29.postimg.org/z0qwv4ryr/figure_2.jpg
您有什么建议吗?

{kind=link}
{kind=link}
matplotlib应该为我处理这个问题。 - Christopher