我正在尝试找到与当前索引相关的最新值不为“NaN”的索引。所以,假设我有一个包含“NaN”值的数据帧如下:
A B C
0 2.1 5.3 4.7
1 5.1 4.6 NaN
2 5.0 NaN NaN
3 7.4 NaN NaN
4 3.5 NaN NaN
5 5.2 1.0 NaN
6 5.0 6.9 5.4
7 7.4 NaN NaN
8 3.5 NaN 5.8
如果我当前在索引4,那么我的值为:
A B C
4 3.5 NaN NaN
我想知道相对于索引4的'B'的最后已知值,该值在索引
1处: A B C
1 5.1 -> 4.6 NaN
我知道使用类似下面的方式可以获取所有具有 NaN 值的索引列表:
indexes = df.index[df['B'].apply(np.isnan)]
但是在大型数据库中,这种方法效率低下。有没有一种方法来相对于当前索引仅tail最后一个元素?
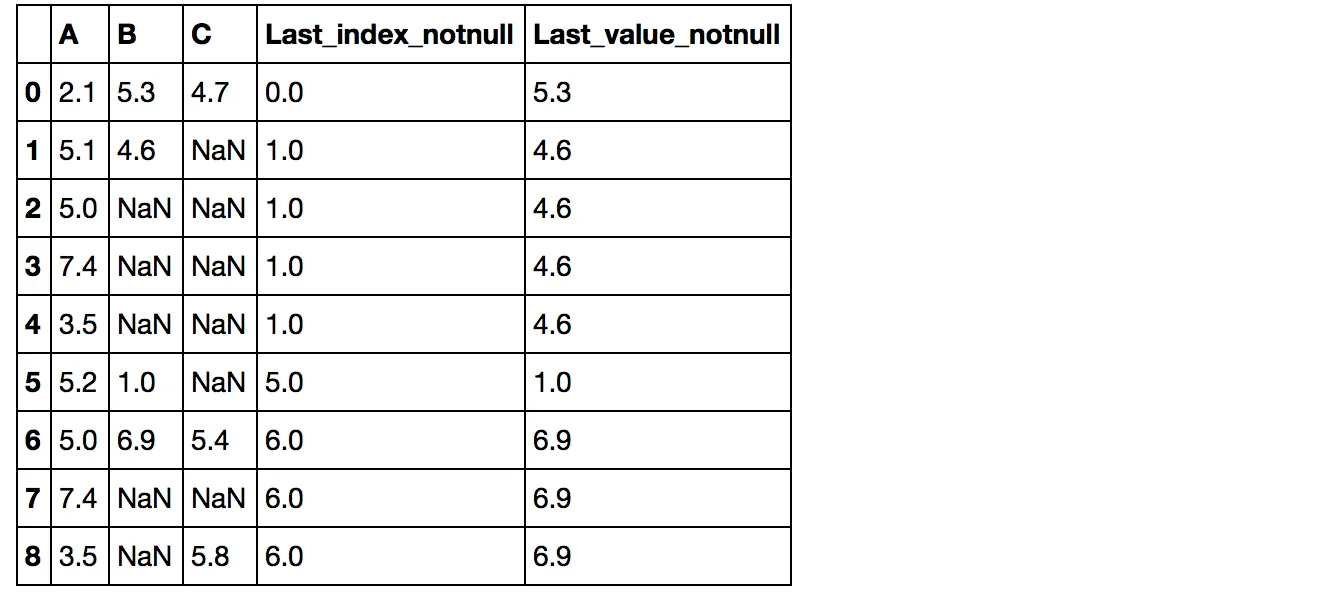
4.6和索引为1。 - alphaleonis4的最新数据还是想查询所有索引的数据? - Psidom