我在Effective STL中注意到,
vector是默认应该使用的序列类型。
这是什么意思?似乎忽略效率,vector都可以胜任任何工作。
请问有没有一种场景,vector不是可行选项而必须使用list的情况?
我在Effective STL中注意到,
vector是默认应该使用的序列类型。
这是什么意思?似乎忽略效率,vector都可以胜任任何工作。
请问有没有一种场景,vector不是可行选项而必须使用list的情况?
| std::vector | std::list |
|---|---|
| 连续的内存。 | 非连续的内存。 |
| 为未来元素预先分配空间,因此除了元素本身所需的空间外,需要额外的空间。 | 没有预先分配的内存。列表本身的内存开销是恒定的。 |
| 每个元素仅需要该元素类型本身的空间(无需额外的指针)。 | 每个元素都需要额外的空间用于保存持有元素的节点,包括指向列表中下一个和前一个元素的指针。 |
| 当添加元素时,可以随时重新分配整个向量的内存。 | 仅添加元素时不必重新分配整个列表的内存。 |
| 在结尾处进行插入具有常数摊销时间,但在其他地方进行插入的时间成本很高(O(n))。 | 无论列表中插入或删除发生在何处,它们都很便宜。 |
| 向量末尾的删除具有常数时间,但对于其余部分,其时间成本为O(n)。 | 使用splice可以轻松地合并列表。 |
| 您可以随机访问其元素。 | 您无法随机访问元素,因此访问列表中特定元素可能很昂贵。 |
| 如果向量添加或删除元素,则迭代器将无效。 | 即使在向列表添加或删除元素时,迭代器也保持有效。 |
| 如果需要元素的数组,则可以轻松获取底层数组。 | 如果需要元素的数组,则必须创建一个新数组并将所有元素添加到其中,因为没有底层数组。 |
一般情况下,如果您不关心使用哪种类型的顺序容器,则使用vector,但是如果您需要对容器中除末尾以外的任何位置进行多次插入或删除操作,则应使用list。或者,如果您需要随机访问,则应使用vector而不是list。除此之外,在实际应用中,基于您的需求,可能需要使用其中一种,但总体而言,这些都是很好的指导方针。
list会释放内存,而vector则不会。除非使用swap()技巧,否则vector在减小大小时不会减少其容量。 - bk1elist有push_front方法。 - Notinlistlist<T> 的一个特殊属性是可以在 O(1) 时间内进行 splice 操作。如果您需要常数时间的拼接操作,那么 list 也可能是最佳选择的数据结构 ;) - Tomasz GandorUglyBlob -- 即使只有几个字符串成员的对象也很容易在复制时产生禁止的高昂成本,因此重新分配一定会代价高昂。 另外:不要忽略指数增长的空间开销,这可能会导致包含几十字节大小对象的vector。(如果您无法提前reserve)。 - Martin Bavector<smart_ptr<Large>> 和 list<Large> -- 我会这么说,如果你需要随机访问元素,那么使用 vector 是有意义的。如果不需要随机访问,则使用 list 更为简单,而且性能也同样好。 - Martin Ba简化问题:
当你在C++中选择容器时,如果感到困惑,请使用以下流程图(感谢我):-
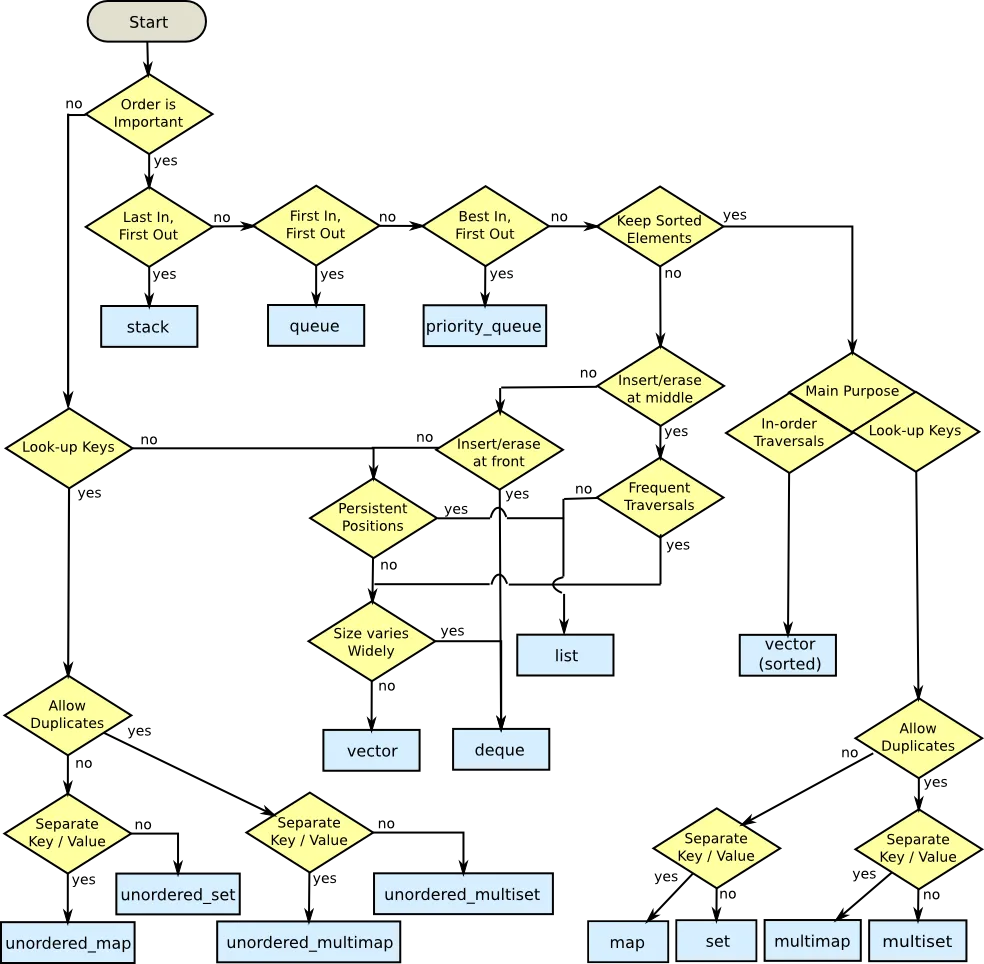
Vector-
List-
std::list的一个特殊能力是splice(将部分或整个列表链接或移动到另一个列表中)。
或者,如果您的内容非常昂贵而无法复制,例如,使用list对集合进行排序可能更便宜。
还要注意,如果集合很小(且内容不太昂贵),则向任何位置插入和删除元素时vector仍然可能比list更高效。列表单独分配每个节点,这可能比移动几个简单对象要费用更高。
我认为没有非常严格的规则。这取决于您想要使用容器做什么,以及您期望容器的大小和包含类型的大小。一般情况下,vector比list更好,因为它将其内容分配为单个连续块(基本上是一个动态分配的数组,在大多数情况下,数组是持有一堆东西最有效的方式)。
list::size 不一定是常数时间。请参见 https://dev59.com/GHVC5IYBdhLWcg3woSxW 和 http://gcc.gnu.org/ml/libstdc++/2005-11/msg00219.html。 - Potatoswatter我的班上的学生似乎无法向我解释在何时使用向量更有效,但他们看起来很高兴地建议我使用列表。
这是我的理解:
列表: 每个项目都包含一个到下一个或前一个元素的地址,因此通过这个功能,即使它们未排序,您也可以随机排列项目,顺序不会改变:如果您的内存是分散的,则效率很高。 但是它还有另一个非常大的优点:您可以轻松地插入/删除项目,因为您唯一需要做的就是更改一些指针。 缺点: 要阅读单个随机项,您必须从一个项目跳转到另一个项目,直到找到正确的地址。
向量: 使用向量时,内存更像普通数组组织:每个n-th项存储在第(n-1)个项之后,在第(n+1)个项之前。 为什么它比列表更好? 因为它允许快速随机访问。 方法如下:如果您知道向量中项目的大小,并且它们在内存中是连续的,那么您可以轻松预测第n个项目在哪里;您不必浏览列表的所有项目以读取您想要的那个,使用向量可以直接读取,使用列表则不能。 另一方面,修改向量数组或更改值要慢得多。
列表更适合跟踪可以在内存中添加/删除的对象。 向量更适合当您想从大量单个项目中访问元素时。
我不知道列表是如何优化的,但您必须知道,如果您想要快速的读取访问,应该使用向量,因为无论STL多么好地加速了列表,它在读取访问方面都不像向量那样快。
vector可能会很慢?如果是这样,那么我同意,但在可以使用reserve()的情况下,可以避免这些问题。 - underscore_d任何时候,您都不能使迭代器无效。
基本上,向量是具有自动内存管理的数组。数据在内存中是连续的。尝试在中间插入数据是一项代价高昂的操作。
在列表中,数据存储在不相关的内存位置中。在中间插入数据不涉及复制部分数据以腾出新空间。
更具体地回答您的问题,我会引用此页面。
向量通常是访问元素、添加或删除序列末尾元素的时间效率最高的数据结构。对于涉及在末尾以外位置插入或删除元素的操作,它们的性能不如双端队列和列表,并且迭代器和引用比列表不够一致。
当你需要在序列中间进行大量插入或删除,例如内存管理器时。