我希望您能够以更简洁的方式为 Pandas groupby 添加小计。以下是我的 DataFrame:
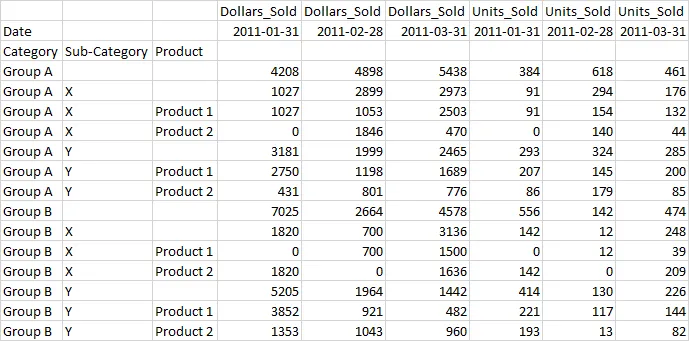
我想为分类和子分类提供小计。我可以使用以下代码实现:
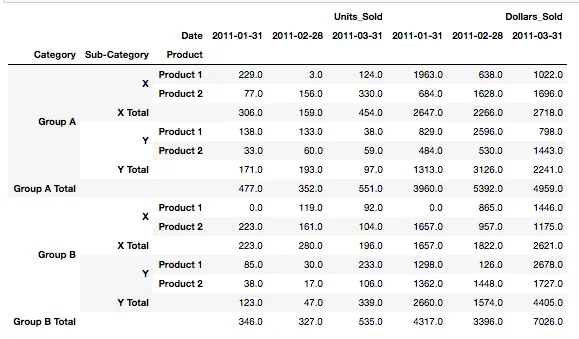
这给我提供了我想要的DataFrame: 最终的DataFrame 我的问题是,除了创建每个级别的新DataFrame然后连接在一起之外,是否有更Pythonic的方法?我已经进行了研究,但找不到更好的方法。我需要对许多不同的MultiIndex数据框执行此操作,并寻求更好的解决方案。
提前感谢您的帮助!
附加信息的编辑:
感谢@Wen和@DaFanat的回复。我尝试使用@Wen提供的链接处理我的数据[链接]:Python(Pandas)在多级索引数据框的每个级别上添加小计
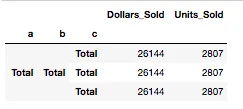
这个代码计算了总和,但忽略了构成列的第二层级别的日期。这导致了这个结果Resulting Image。
我已经尝试使用TimeGrouper和groupby一起使用,但出现了错误。非常感谢您的帮助!谢谢!
df = pd.DataFrame({
'Category':np.random.choice( ['Group A','Group B'], 50),
'Sub-Category':np.random.choice( ['X','Y'], 50),
'Product':np.random.choice( ['Product 1','Product 2'], 50),
'Units_Sold':np.random.randint(1,100, size=(50)),
'Dollars_Sold':np.random.randint(100,1000, size=50),
'Date':np.random.choice( pd.date_range('1/1/2011','03/31/2011',
freq='D'), 50, replace=False)})
从那里开始,我会创建一个新的分组数据框,如下所示:
df1 = df.groupby(['Category','Sub-Category','Product',pd.TimeGrouper(key='Date',freq='M')]).agg({'Units_Sold':'sum','Dollars_Sold':'sum'}).unstack().fillna(0)
我想为分类和子分类提供小计。我可以使用以下代码实现:
df2 = df1.groupby(level=[0,1]).sum()
df2.index = pd.MultiIndex.from_arrays([df2.index.get_level_values(0),
df2.index.get_level_values(1) + ' Total',
len(df2) * ['']])
df3 = df1.groupby(level=[0]).sum()
df3.index = pd.MultiIndex.from_arrays([df3.index.get_level_values(0) + ' Total',
len(df3) * [''],
len(df3) * ['']])
pd.concat([df1,df2,df3]).sort_index()
这给我提供了我想要的DataFrame: 最终的DataFrame 我的问题是,除了创建每个级别的新DataFrame然后连接在一起之外,是否有更Pythonic的方法?我已经进行了研究,但找不到更好的方法。我需要对许多不同的MultiIndex数据框执行此操作,并寻求更好的解决方案。
提前感谢您的帮助!
附加信息的编辑:
感谢@Wen和@DaFanat的回复。我尝试使用@Wen提供的链接处理我的数据[链接]:Python(Pandas)在多级索引数据框的每个级别上添加小计
pd.concat([df.assign(\
**{x: 'Total' for x in "CategorySub-CategoryProduct"[i:]}\
).groupby(list('abc')).sum() for i in range(1,4)])\
.sort_index()
这个代码计算了总和,但忽略了构成列的第二层级别的日期。这导致了这个结果Resulting Image。
我已经尝试使用TimeGrouper和groupby一起使用,但出现了错误。非常感谢您的帮助!谢谢!
{kind=link}
{kind=link}