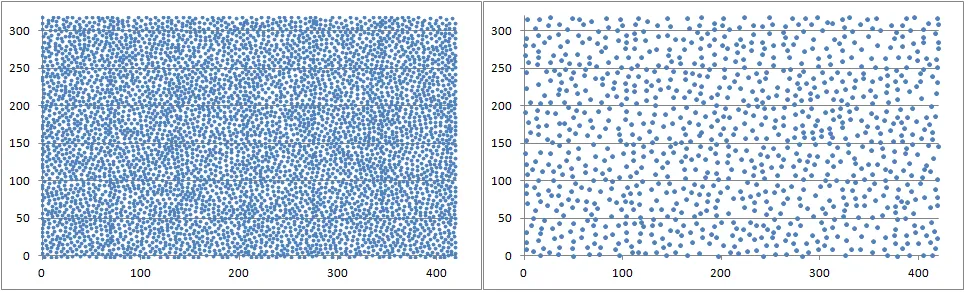
我已成功实现了Mitchell的最佳候选算法。Mitchell的最佳候选算法通过创建k个候选样本并选择最佳的k个样本来生成新的随机样本。这里“最佳”样本的定义是与之前样本最远的样本。该算法近似于泊松盘采样,产生比均匀随机采样更自然的外观(更好的蓝噪声光谱特性)。
我正在尝试改进它,特别是在速度方面。因此,我想到的第一个想法是将候选样本仅与最后添加的元素进行比较,而不是将它们与整个以前的样本进行比较。这会偏向泊松盘采样,但可能会产生一些有趣的结果。
以下是我的实现的主要部分。
我正在尝试改进它,特别是在速度方面。因此,我想到的第一个想法是将候选样本仅与最后添加的元素进行比较,而不是将它们与整个以前的样本进行比较。这会偏向泊松盘采样,但可能会产生一些有趣的结果。
以下是我的实现的主要部分。
public class MitchellBestCandidateII extends JFrame {
private List<Point> mitchellPoints = new ArrayList<Point>();
private Point currentPoint;
private int currentPointIndex =0;
private boolean isBeginning = true;
private Point[] candidatesBunch = new Point[MAX_CANDIDATES_AT_TIME];
public MitchellBestCandidateII() {
computeBestPoints();
initComponents();
}
computeBestPoints方法在计算点时与Mitchell算法不同,它仅将候选点与上一个添加的点进行比较,而不是将其与整个样本进行比较。
private void computeBestPoints() {
do {
if (isBeginning) {
currentPoint = getRandomPoint();
mitchellPoints.add(currentPoint);
isBeginning = false;
currentPointIndex = 0;
}
setCandidates();
Point bestCandidate = pickUpCandidateFor(currentPoint);
mitchellPoints.add(bestCandidate);
currentPoint = bestCandidate;
currentPointIndex++;
} while (currentPointIndex <MAX_NUMBER_OF_POINTS);
}
private Point pickUpCandidateFor(Point p) {
double biggestDistance = 0.0D;
Point result = null;
for (int i = 0; i < MAX_CANDIDATES_AT_TIME; i++) {
double d = distanceBetween(p, candidatesBunch[i]);
if (biggestDistance < d) {
biggestDistance = d;
result = candidatesBunch[i];
}
}
return result;
}
setCandidates方法会生成随机的候选项,只有其中一个会成为样本的一部分,其余的将被舍弃。
private void setCandidates() {
for (int i = 0; i < MAX_CANDIDATES_AT_TIME; i++) {
candidatesBunch[i] = getRandomPoint();
}
}
private Point getRandomPoint() {
return new Point(Randomizer.getHelper().nextInt(SCREEN_WIDTH), Randomizer.getHelper().nextInt(SCREEN_HEIGHT));
}
initComponents是设置JFrame和JPanel的方法,并将要绘制的点列表传递给JPanel。 private void initComponents() {
this.setSize(SCREEN_WIDTH,SCREEN_HEIGHT);
PaintPanel panel = new PaintPanel(mitchellPoints);
panel.setPreferredSize(new Dimension(SCREEN_WIDTH,SCREEN_HEIGHT));
this.setContentPane(panel);
this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}
distanceBetween方法计算两点之间的距离,应用了数学公式。 public double distanceBetween(Point p1, Point p2) {
double deltaX = p1.getX() - p2.getX();
double deltaY = p1.getY() - p2.getY();
double deltaXSquare = Math.pow(deltaX, 2);
double deltaYSquare = Math.pow(deltaY, 2);
return Math.sqrt(deltaXSquare + deltaYSquare);
}
}
下面是执行的示意图:
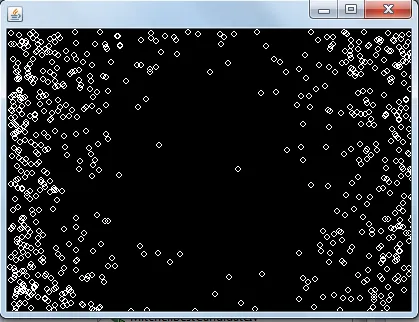
每次运行似乎都会产生相同类型的点分布,正如您在上面的图片中所看到的,这些点似乎会避开中心区域。我不明白为什么会出现这种情况。有人能帮我理解这种行为吗?是否有其他方法(或已知算法)可以显着改进Mitchell的最佳候选算法?我的Mitchell最佳候选算法实现(不是上面的代码)正在Code Review上进行审查。
感谢您的帮助。