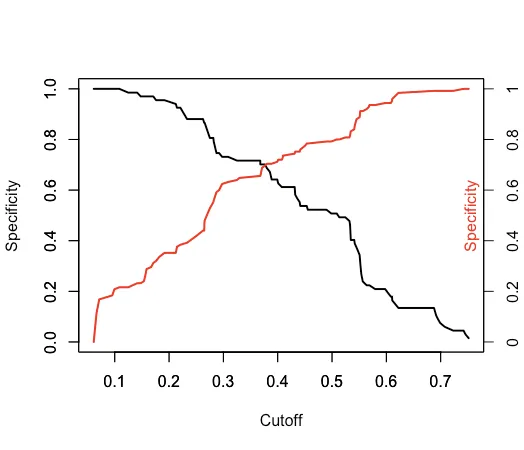
在尝试复制第一个图表时四处使用工具。给定一个
predictions <- prediction(pred,labels) 对象,然后使用基础R方法。
plot(unlist(performance(predictions, "sens")@x.values), unlist(performance(predictions, "sens")@y.values),
type="l", lwd=2, ylab="Specificity", xlab="Cutoff")
par(new=TRUE)
plot(unlist(performance(predictions, "spec")@x.values), unlist(performance(predictions, "spec")@y.values),
type="l", lwd=2, col='red', ylab="", xlab="")
axis(4, at=seq(0,1,0.2),labels=z)
mtext("Specificity",side=4, padj=-2, col='red')
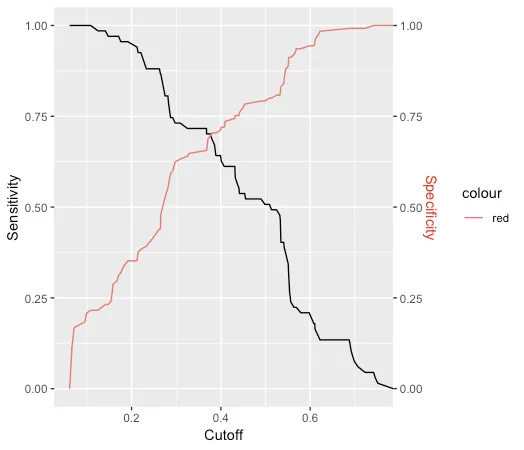
"ggplot2方法
"
sens <- data.frame(x=unlist(performance(predictions, "sens")@x.values),
y=unlist(performance(predictions, "sens")@y.values))
spec <- data.frame(x=unlist(performance(predictions, "spec")@x.values),
y=unlist(performance(predictions, "spec")@y.values))
sens %>% ggplot(aes(x,y)) +
geom_line() +
geom_line(data=spec, aes(x,y,col="red")) +
scale_y_continuous(sec.axis = sec_axis(~., name = "Specificity")) +
labs(x='Cutoff', y="Sensitivity") +
theme(axis.title.y.right = element_text(colour = "red"), legend.position="none")