这是我的查询,需要 17.9397 秒 的时间才能得到响应:
SELECT allbar.iBarID AS iBarID,
allbar.vName AS vName,
allbar.tAddress AS tAddress,
allbar.tDescription AS tDescription,
(SELECT COUNT(*)
FROM tbl_post p
WHERE p.vBarIDs = allbar.iBarID) AS `total_post`,
allbar.bar_usbg AS bar_usbg,
allbar.bar_enhance AS bar_enhance,
(SELECT count(*)
FROM tbl_user
WHERE FIND_IN_SET(allbar.iBarID,vBarIDs)
AND (eType = 'Bartender'
OR eType = 'Bar Manager'
OR eType = 'Bar Owner')) AS countAss,
allbar.eStatus AS eStatus
FROM
(SELECT DISTINCT b.iBarID AS iBarID,
b.vName AS vName,
b.tAddress AS tAddress,
(CASE LENGTH(b.tDescription) WHEN 0 THEN '' WHEN LENGTH(b.tDescription) > 0
AND LENGTH(b.tDescription) < 50 THEN CONCAT(LEFT(b.tDescription, 50),'...') ELSE b.tDescription END) AS tDescription,
b.usbg AS bar_usbg,
b.enhance AS bar_enhance,
b.eStatus AS eStatus
FROM tbl_bar b,
tbl_user u
WHERE b.iBarID <> '-10') AS allbar
我已经尝试了EXPLAIN,以下是结果:
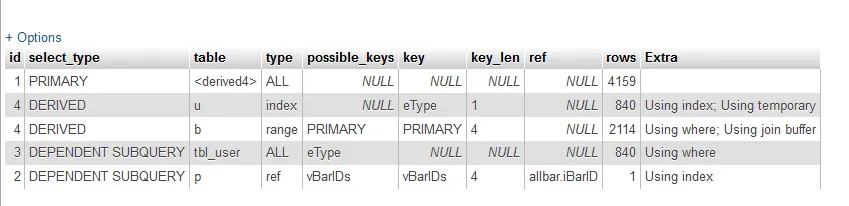
有人能解释一下这个EXPLAIN的结果吗?