希望你一切都好。
我需要在这个数据库上稍微帮忙一下:
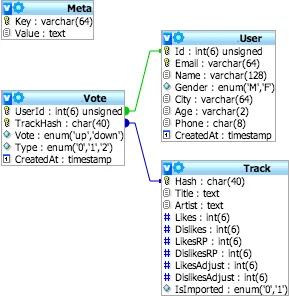
这是一个存储投票的数据库。用户选择他们喜欢的音轨,并为它们投票。他们可以投赞成票或反对票。非常简单。但是,当涉及计算统计数据时,情况就变得复杂了。
元信息
这是一个键-值样式的表格,存储最常用的统计数据(类似于缓存):
mysql> SELECT * FROM Meta;
+-------------+-------+
| Key | Value |
+-------------+-------+
| TRACK_COUNT | 2620 |
| VOTE_COUNT | 3821 |
| USER_COUNT | 371 |
+-------------+-------+
投票
投票表格保存了投票内容。这里唯一有趣的字段是Type,其值的含义如下:
0- 应用程序制作的投票,用户使用UI投票给曲目1- 导入的投票(来自外部服务)2- 合并的投票。实际上与导入的投票相同,但它实际上是一个注释,表示该用户已经使用外部服务为此曲目投票,现在他正在使用应用程序重复投票。
曲目
曲目保存了自身的总体统计信息。点赞数、踩数、来自外部服务的点赞数 (LikesRP)、来自外部服务的踩数 (DislikesRP),以及点赞/踩的调整。
应用程序
应用程序需要获取以下投票信息:
- 过去7天内5个最受欢迎的曲目
- 过去7天内5个最不受欢迎的曲目
- 过去7天内从外部服务导入的5个最受欢迎的曲目的投票 (
Vote.Type = 1) - 过去一个月内100个最受欢迎的曲目
为了获取100个最受欢迎的曲目,我使用以下查询:
SELECT
T.Hash,
T.Title,
T.Artist,
COALESCE(X.VotesTotal, 0) + T.LikesAdjust as VotesAdjusted
FROM (
SELECT
V.TrackHash,
SUM(V.Vote) AS VotesTotal
FROM
Vote V
WHERE
V.CreatedAt > NOW() - INTERVAL 1 MONTH AND V.Vote = 'up'
GROUP BY
V.TrackHash
ORDER BY
VotesTotal DESC
) X
RIGHT JOIN Track T
ON T.Hash = X.TrackHash
ORDER BY
VotesAdjusted DESC
LIMIT 0, 100;
这个查询工作正常,并且考虑了调整(客户想要在列表中调整轨迹位置)。几乎相同的查询用于获取5个最高/最低投票的轨迹。任务#3的查询如下:
SELECT
T.Hash,
T.Title,
T.Artist,
COALESCE(X.VotesTotal, 1) as VotesTotal
FROM (
SELECT
V.TrackHash,
SUM(V.Vote) AS VotesTotal
FROM
Vote V
WHERE
V.Type = '1' AND
V.CreatedAt > NOW() - INTERVAL 1 WEEK AND
V.Vote = 'up'
GROUP BY
V.TrackHash
ORDER BY
VotesTotal DESC
) X
RIGHT JOIN Track T
ON T.Hash = X.TrackHash
ORDER BY
VotesTotal DESC
LIMIT 0, 5;
问题在于第一个查询需要大约2秒钟才能执行,而我们只有不到4k的投票。到年底,这个数字将达到大约200k的投票,这很可能会让这个数据库崩溃。所以我正在想办法解决这个难题。
现在我得出以下问题:
1. 我的数据库设计错了吗?我的意思是,它可以更好吗? 2. 我查询的方法有误吗? 3. 我还能做些什么改进吗?
我做的第一件事情是缓存。但是,好吧,这解决了问题。但是我对与SQL相关的解决方案很感兴趣(总是追求完美)。
我想到的第二件事情是将这些计算值放到“Meta”表中,并在投票过程中更改它们。但是我时间很紧,没有时间去尝试。顺便问一下,这样做值得吗?或者,企业级应用程序如何解决这些问题?
谢谢。
编辑:
我简直不敢相信我忘记包含索引了。这里它们是:
mysql> SHOW INDEXES IN Vote;
+-------+------------+-------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+-------+------------+-------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+
| Vote | 0 | UNIQUE_UserId_TrackHash | 1 | UserId | A | 890 | NULL | NULL | | BTREE | |
| Vote | 0 | UNIQUE_UserId_TrackHash | 2 | TrackHash | A | 4450 | NULL | NULL | | BTREE | |
| Vote | 1 | INDEX_TrackHash | 1 | TrackHash | A | 4450 | NULL | NULL | | BTREE | |
| Vote | 1 | INDEX_CreatedAt | 1 | CreatedAt | A | 1483 | NULL | NULL | | BTREE | |
| Vote | 1 | UserId | 1 | UserId | A | 1483 | NULL | NULL | | BTREE | |
+-------+------------+-------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+
mysql> SHOW INDEXES IN Track;
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+
| Track | 0 | PRIMARY | 1 | Hash | A | 2678 | NULL | NULL | | BTREE | |
| Track | 1 | INDEX_Likes | 1 | Likes | A | 66 | NULL | NULL | | BTREE | |
| Track | 1 | INDEX_Dislikes | 1 | Dislikes | A | 27 | NULL | NULL | | BTREE | |
+-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+