介绍
我很喜欢你的问题,所以我尝试使用MySQL并尝试找到问题的源头。为此,我创建了一些测试。
数据
我使用一个叫做随机数据生成器的工具生成了10万行样本数据(文档有点过时,但仍然可用)。我传递给gendata.pl的配置文件如下。
$tables = {
rows => [100000],
names => ['ebay_items'],
engines => ['MyISAM'],
pk => ['int auto_increment']
};
$fields = {
types => ['datetime', 'int'],
indexes => [undef]
};
$data = {
numbers => [
'tinyint unsigned',
'smallint unsigned',
'smallint unsigned',
'mediumint unsigned'
],
temporals => ['datetime']
};
我已经运行了两个不同的测试批次:一个使用了MyISAM表,另一个使用了InnoDB。(因此,您只需在上面的片段中将MyISAM替换为InnoDB即可。)
表格
该工具创建了一个表格,其中列被称为pk、col_datetime和col_int。 我已经重命名它们以匹配您的表格列。 生成的表格如下所示。
+---------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+----------+------+-----+---------+----------------+
| endtime | datetime | YES | MUL | NULL | |
| id | int(11) | NO | PRI | NULL | auto_increment |
| price | int(11) | YES | MUL | NULL | |
+---------+----------+------+-----+---------+----------------+
索引
该工具不会自动创建索引,因为我希望手动创建它们。
CREATE INDEX `endtime` ON `ebay_items` (endtime, price);
CREATE INDEX `price` ON `ebay_items` (price, endtime);
CREATE INDEX `endtime_only` ON `ebay_items` (endtime);
CREATE INDEX `price_only` ON `ebay_items` (price);
查询
我使用的查询语句。
SELECT `ebay_items`.*
FROM `ebay_items`
FORCE INDEX (`endtime|price|endtime_only|price_only`)
WHERE (`endtime` > '2009-01-01' - INTERVAL 1 MONTH)
ORDER BY `price` DESC
(有一个索引可以使用四个不同的查询。我在这里使用了 2009-01-01 代替 NOW(),因为该工具似乎生成的日期都在2009年左右。)
解释
下面是针对MyISAM(顶部)和InnoDB(底部)表中每个索引的上述查询的EXPLAIN输出。
endtime
id: 1
select_type: SIMPLE
table: ebay_items
type: range
possible_keys: endtime
key: endtime
key_len: 9
ref: NULL
rows: 25261
Extra: Using where; Using filesort
id: 1
select_type: SIMPLE
table: ebay_items
type: range
possible_keys: endtime
key: endtime
key_len: 9
ref: NULL
rows: 21026
Extra: Using where; Using index; Using filesort
价格
id: 1
select_type: SIMPLE
table: ebay_items
type: index
possible_keys: NULL
key: price
key_len: 14
ref: NULL
rows: 100000
Extra: Using where
id: 1
select_type: SIMPLE
table: ebay_items
type: index
possible_keys: NULL
key: price
key_len: 14
ref: NULL
rows: 100226
Extra: Using where; Using index
endtime_only
id: 1
select_type: SIMPLE
table: ebay_items
type: range
possible_keys: endtime_only
key: endtime_only
key_len: 9
ref: NULL
rows: 11666
Extra: Using where; Using filesort
id: 1
select_type: SIMPLE
table: ebay_items
type: range
possible_keys: endtime_only
key: endtime_only
key_len: 9
ref: NULL
rows: 21270
Extra: Using where; Using filesort
仅价格
id: 1
select_type: SIMPLE
table: ebay_items
type: index
possible_keys: NULL
key: price_only
key_len: 5
ref: NULL
rows: 100000
Extra: Using where
id: 1
select_type: SIMPLE
table: ebay_items
type: index
possible_keys: NULL
key: price_only
key_len: 5
ref: NULL
rows: 100226
Extra: Using where
根据这些信息,我决定在测试中使用endtime_only索引,因为我需要针对MyISAM表和InnoDB表运行查询。但是,正如你所看到的,最合理的endtime索引似乎是最好的选择。
测试
为了测试使用MyISAM表和InnoDB表时查询的效率(关于生成的I/O活动),我编写了以下简单的Java程序。
static final String J = "jdbc:mysql://127.0.0.1:3306/test?user=root&password=root";
static final String Q = "SELECT * FROM ebay_items FORCE INDEX (endtime_only) WHERE (endtime > '2009-01-01'-INTERVAL 1 MONTH) ORDER BY price desc;";
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 1000; i++)
try (Connection c = DriverManager.getConnection(J);
Statement s = c.createStatement()) {
TimeUnit.MILLISECONDS.sleep(10L);
s.execute(Q);
} catch (SQLException ex) {
ex.printStackTrace();
}
}
设置
我在戴尔Vostro 1015笔记本电脑上运行了Windows二进制MySQL 5.5,处理器为Intel Core Duo T6670 @ 2.20 GHz,内存为4 GB。Java程序通过TCP/IP与MySQL服务器进程通信。
状态
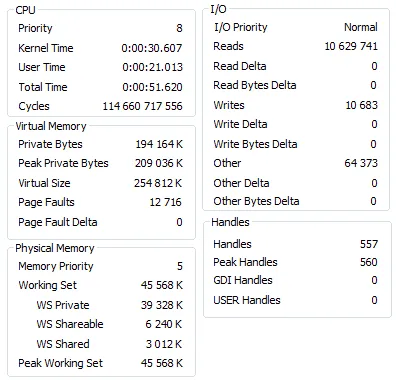
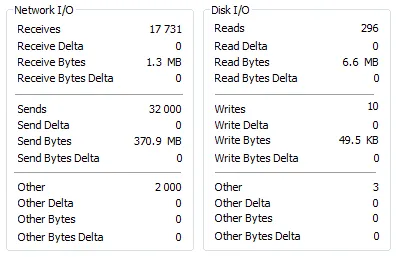
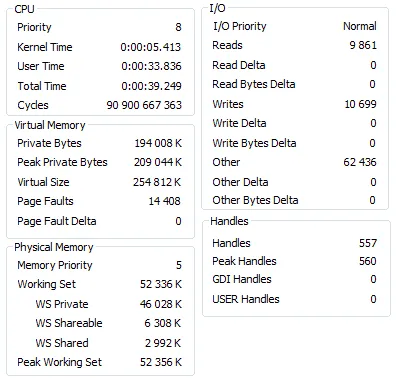
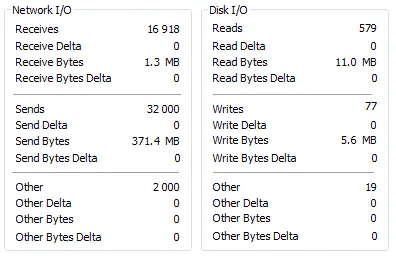
我使用Process Explorer捕获了针对MyISAM和InnoDB表运行测试之前和之后的mysqld进程状态。
之前
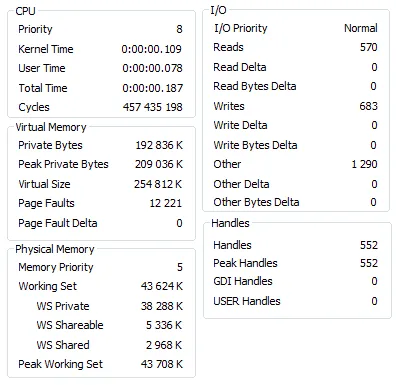
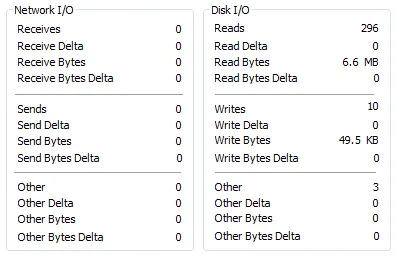
之后—MyISAM
之后—InnoDB
结论
基本上,两次运行只有在使用MyISAM引擎的表时才存在大量单独的I/O读取。这两个测试都运行了50-60秒。在使用MyISAM时,CPU的最大负载约为42%,而在使用InnoDB时约为38%。
我不太确定高数量的I/O读取的影响是什么,但在这种情况下,较小的数字更好(可能)。如果您的表中有一些其他列(而不是您指定的列),并且具有一些非默认的MySQL配置(关于缓冲区大小等),则可能会使用磁盘资源。
price列上有索引吗? - Andronicusprice列上没有明确的索引。你认为这会有帮助吗? - Will SulzerWHERE和GROUP BY有不同键时的行为。你只需要特定范围内的“一个月前以内”的数据吗?如果是的话,我建议你创建不同的表来保存这个类别中的数据和其他数据。也许可以使用ebay_items表来存储活跃的月份,然后定期将超过一个月的项目移动到ebay_items_history或类似的表中。 - Andronicus