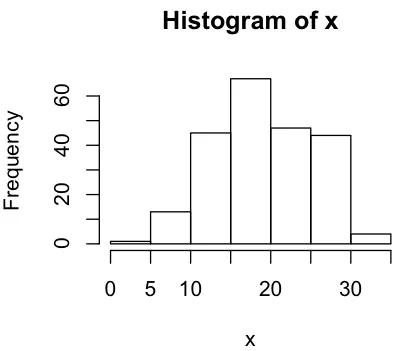
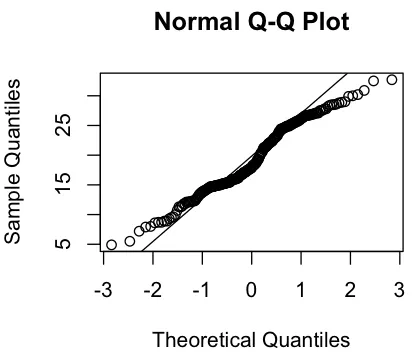
我正在对我的数据进行正态性检验。通常,我期望数据是近似正态分布的(足够正态),这得到了原始值的直方图和QQ图的支持。
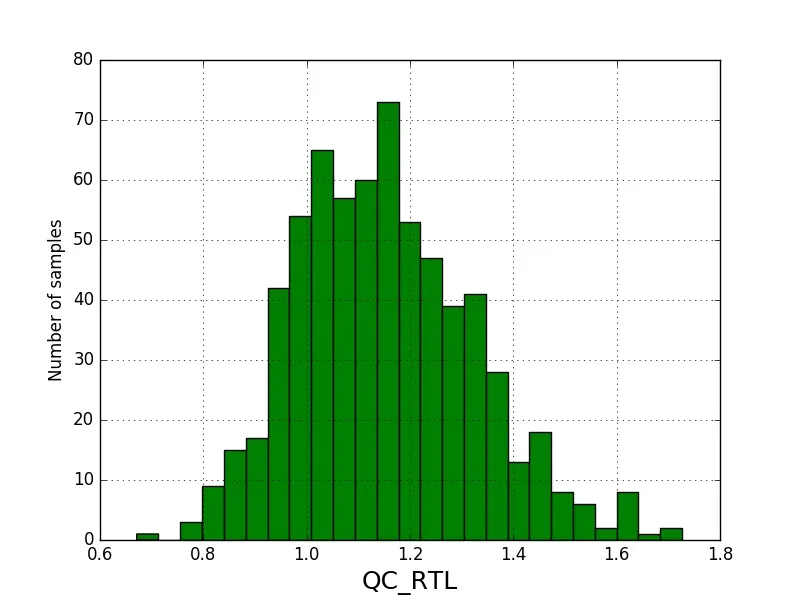
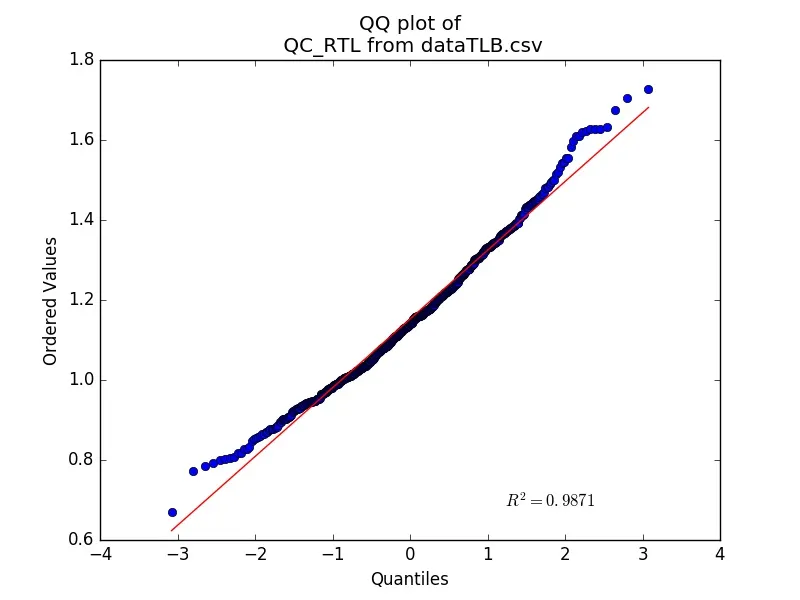 我已经执行了Kolmogorov-Smirnov和Shapiro-Wilk测试,这就是我感到困惑的地方。我的p值几乎为0。
Kolmogorov-Smirnov统计量=0.78,p值=0.0
Shapiro-Wilk统计量=0.99,p值=1.2e-05
这让我相信我应该拒绝零假设。
我原本认为这是由于我的均值和标准差与KS测试所假设的0和1不同,如此处所解释的,但后来在plotly的正态性测试教程中发现,对于两个测试,低p值似乎支持零假设!
plotly正态性测试教程
是否更改了测试的执行方式?还是教程页面上有错误?
我已经执行了Kolmogorov-Smirnov和Shapiro-Wilk测试,这就是我感到困惑的地方。我的p值几乎为0。
Kolmogorov-Smirnov统计量=0.78,p值=0.0
Shapiro-Wilk统计量=0.99,p值=1.2e-05
这让我相信我应该拒绝零假设。
我原本认为这是由于我的均值和标准差与KS测试所假设的0和1不同,如此处所解释的,但后来在plotly的正态性测试教程中发现,对于两个测试,低p值似乎支持零假设!
plotly正态性测试教程
是否更改了测试的执行方式?还是教程页面上有错误?