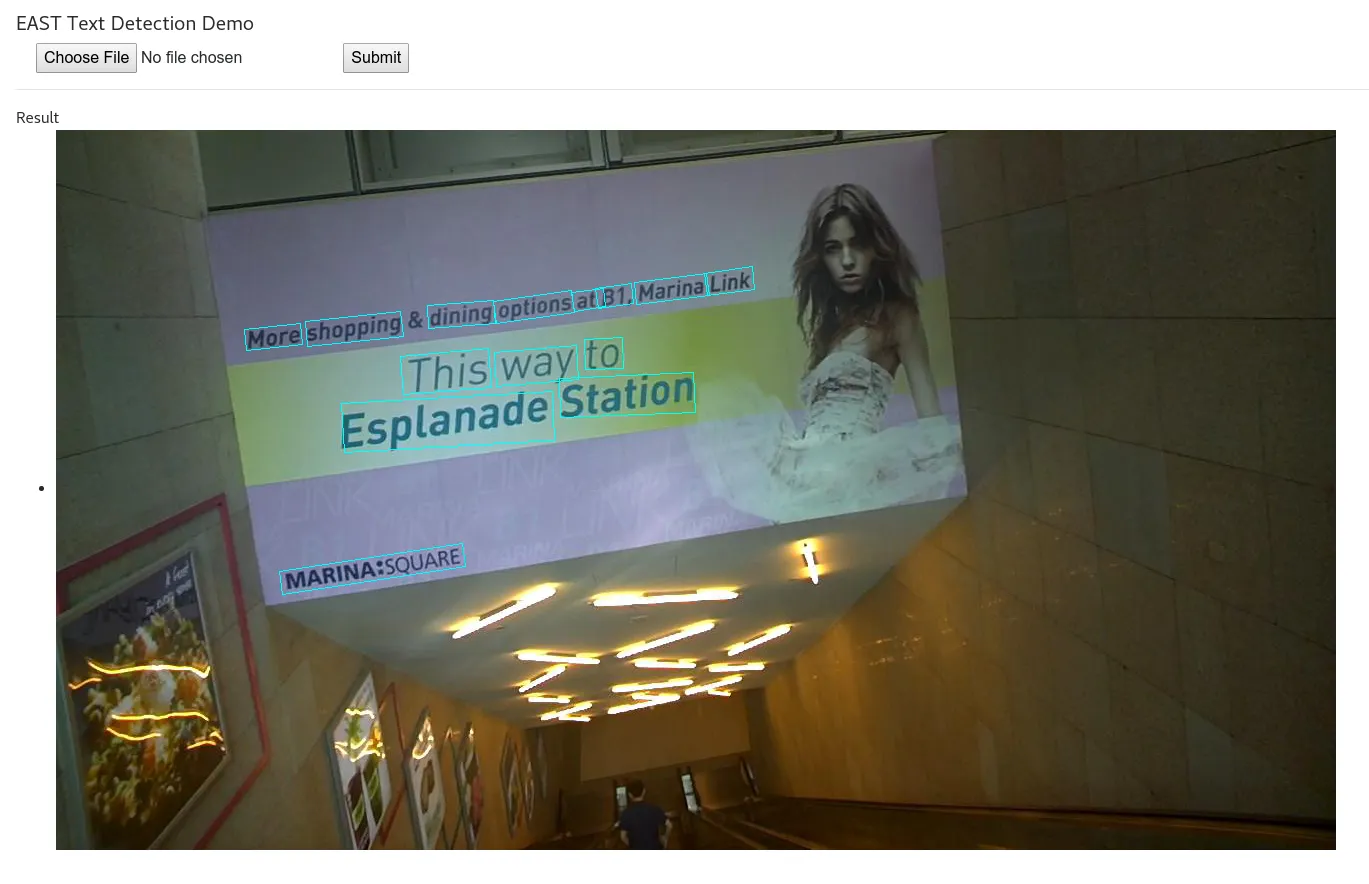
我正在一个项目中工作,需要对标签上的文字进行OCR。我的任务是将图像校正,使其可以被tesseract识别。
 上有效,但对于有背景的图片(如所呈现的图片)则无效。在那里,它计算出了0.0的倾斜角度,没有旋转图像。(期望结果:17°)
上有效,但对于有背景的图片(如所呈现的图片)则无效。在那里,它计算出了0.0的倾斜角度,没有旋转图像。(期望结果:17°)
我尝试过背景去除,但找不到足够好的方法,只留下带有文本的标签。
我尝试了另一种方法,即通过k-means聚类来聚集像素。但即使手动选择一个好的k值,包含文本的聚类仍然包含部分背景。
如何最好地校正具有背景的图像?

上有效,但对于有背景的图片(如所呈现的图片)则无效。在那里,它计算出了0.0的倾斜角度,没有旋转图像。(期望结果:17°)

我尝试过背景去除,但找不到足够好的方法,只留下带有文本的标签。
我尝试了另一种方法,即通过k-means聚类来聚集像素。但即使手动选择一个好的k值,包含文本的聚类仍然包含部分背景。

如何最好地校正具有背景的图像?