是的,我已经阅读了this和this answer,但我仍然无法理解...这是一个基本问题。
输入:
M[:, index]
M[index, :]
哪一个是行切片,哪一个是列切片?
关于我的问题,如果我想要对列进行高级索引,应该怎么做呢:
M[:, indexes] # indexes is an array like [0, 4, 9]
是的,我已经阅读了this和this answer,但我仍然无法理解...这是一个基本问题。
输入:
M[:, index]
M[index, :]
哪一个是行切片,哪一个是列切片?
关于我的问题,如果我想要对列进行高级索引,应该怎么做呢:
M[:, indexes] # indexes is an array like [0, 4, 9]
实际上,row/column slicing 都不是:它们是 row/column indexing 的例子。
M[index, :] 是 row indexingM[:, index] 是 column indexingM[start:stop, :] 是 row slicingM[:, start:stop] 是 column slicingCSC 在检索整个列方面更加高效:特定列的非零值及其匹配的行索引在内部存储为连续的数组。
CSR 则针对整行的检索更加高效。
: 是切片,所以才会对 M[:, index] 表示列的切片感到困惑。所以您的意思是,: 并不是真正的切片,它只是表示“所有”,然后我只是对列进行索引。此外,对于我的情况,我并不是真正地对列进行切片,而只是进行索引(正如您所说)。CSC 对我的情况更好,不完全是因为这种类型在切片方面更好,而更普遍地说,它在检索整个列方面更好——正确吗? - juanmirocks:单独使用是None:None的简写,表示该轴周围的完整切片,相当于根本没有切片;是的,CSC更适合检索整个列(通过对列的子集进行切片和索引特定列)。 - ogrisel: 的困惑,因此回答了我的问题 :-) -- 切片还是不切片 - juanmirocks虽然对于 csr 选择行比选择列更快,但差异并不大:
In [288]: Mbig=sparse.rand(1000,1000,.1, 'csr')
In [289]: Mbig[:1000:50,:]
Out[289]:
<20x1000 sparse matrix of type '<class 'numpy.float64'>'
with 2066 stored elements in Compressed Sparse Row format>
In [290]: timeit Mbig[:1000:50,:]
1000 loops, best of 3: 1.53 ms per loop
In [291]: timeit Mbig[:,:1000:50]
100 loops, best of 3: 2.04 ms per loop
In [292]: Mbig=sparse.rand(1000,1000,.1, 'csc')
In [293]: timeit Mbig[:1000:50,:]
100 loops, best of 3: 2.16 ms per loop
In [294]: timeit Mbig[:,:1000:50]
1000 loops, best of 3: 1.65 ms per loop
更改格式不值得
In [295]: timeit Mbig.tocsr()[:1000:50,:]
...
100 loops, best of 3: 2.46 ms per loop
In [297]: A=Mbig.A
In [298]: timeit A[:,:1000:50]
...
1000000 loops, best of 3: 557 ns per loop
In [301]: timeit A[:,:1000:50].copy()
...
10000 loops, best of 3: 52.5 µs per loop
numpy高级功能)实际上比使用“切片”更快:In [308]: idx=np.r_[0:1000:50] # expand slice into array
In [309]: timeit Mbig[idx,:]
1000 loops, best of 3: 1.49 ms per loop
In [310]: timeit Mbig[:,idx]
1000 loops, best of 3: 513 µs per loop
这里的列索引具有更快的速度提升。
对于单行或单列,csr和csc都有getrow/col方法:
In [314]: timeit Mbig.getrow(500)
1000 loops, best of 3: 434 µs per loop
In [315]: timeit Mbig.getcol(500) # 1 column from csc is fastest
10000 loops, best of 3: 78.7 µs per loop
In [316]: timeit Mbig[500,:]
1000 loops, best of 3: 505 µs per loop
In [317]: timeit Mbig[:,500]
1000 loops, best of 3: 264 µs per loop
在https://dev59.com/N5rga4cB1Zd3GeqPrsSs#39500986中,我重新创建了sparse用于获取行或列的extractor代码。它构建一个新的稀疏的“向量”,其中包含1和0,并使用矩阵乘法来“选择”行或列。
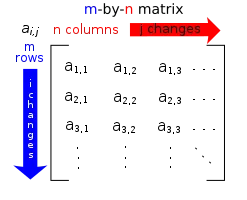
: 表示全部,你就知道 [:, i] 表示所有行,而 [i, :] 表示所有列。M[:, indices],所以诀窍在于名称:如果你循环遍历列(因为你为所有行指定了列索引),那么你需要使用压缩稀疏列格式。在你提供的文档中已经说明了这一点:
CSC 格式的优势
- ...
- 高效的列切片
[:, i] 是列切片,这就是为什么我想使用 CSC - 对吗? - juanmirocks
ndarray不同。它看起来相同,但实际上是通过矩阵乘法实现的。因此,基本索引和高级索引以及复制和视图之间的区别不适用。如果您担心速度问题,请自行计时。 - hpaulj