如何在R中执行RMSE
请参考我在另一个回答中获得了97个以上的赞同的Python实现RMSE:https://dev59.com/5mQm5IYBdhLWcg3w-S6Y#37861832。以下是R代码的解释。
RMSE(均方根误差)、MSE(均方误差)和RMS(均方根)都是用于比较两个数列之间变化的数学技巧。
RMSE提供了一个单一的数字来回答问题:“list1和list2中的数字平均而言有多相似?”这两个列表必须大小相同。我想要“消除任意两个给定元素之间的噪音,消除收集的数据量,并获得关于时间变化的单一数字感觉”。
对RMSE的直观理解:
想象一下你正在学习投掷飞镖。每天你练习一个小时。你想知道你是变得更好还是变得更差。所以每天你扔10次飞镖并测量靶心和你的飞镖落点之间的距离。
你制作了一个这些距离的列表。使用第1天到包含所有零的列表之间的均方根误差。在第2天和第n天也使用相同的方法。你将得到一个单一数字,希望随着时间的推移而减少。当您的RMSE数字为零时,每次都能打中靶心。如果数字增加,你变得更差。
在R中计算均方根误差的示例:
cat("Inputs are:\n")
d = c(0.000, 0.166, 0.333)
p = c(0.000, 0.254, 0.998)
cat("d is: ", toString(d), "\n")
cat("p is: ", toString(p), "\n")
rmse = function(predictions, targets){
cat("===RMSE readout of intermediate steps:===\n")
cat("the errors: (predictions - targets) is: ",
toString(predictions - targets), '\n')
cat("the squares: (predictions - targets) ** 2 is: ",
toString((predictions - targets) ** 2), '\n')
cat("the means: (mean((predictions - targets) ** 2)) is: ",
toString(mean((predictions - targets) ** 2)), '\n')
cat("the square root: (sqrt(mean((predictions - targets) ** 2))) is: ",
toString(sqrt(mean((predictions - targets) ** 2))), '\n')
return(sqrt(mean((predictions - targets) ** 2)))
}
cat("final answer rmse: ", rmse(d, p), "\n")
这将打印出:
Inputs are:
d is: 0, 0.166, 0.333
p is: 0, 0.254, 0.998
===RMSE Explanation of steps:===
the errors: (predictions - targets) is: 0, -0.088, -0.665
the squares: (predictions - targets) ** 2 is: 0, 0.007744, 0.442225
the means: (mean((predictions - targets) ** 2)) is: 0.149989666666667
the square root: (sqrt(mean((predictions - targets) ** 2))) is: 0.387284994115014
final answer rmse: 0.387285
数学符号:
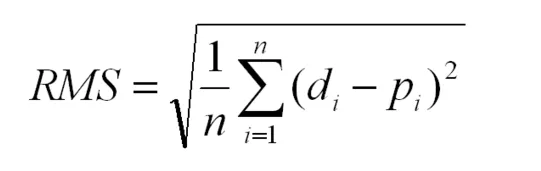
RMSE不是最准确的线性拟合策略,总体最小二乘法是更好的选择:
均方根误差测量点和线之间的垂直距离,因此如果您的数据形状像香蕉,底部平坦,顶部陡峭,则RMSE将报告高处点的距离更远,但实际上与低处点相比距离相等。这会导致偏差,使线更喜欢靠近高点而不是低点。
如果这是一个问题,那么总体最小二乘法可以解决这个问题:
https://mubaris.com/posts/linear-regression/
可能导致此RMSE函数出错的注意事项:
如果任一输入列表中存在空值或无限大值,则输出RMSE值将没有意义。 处理任一列表中的nulls / missing values / infinities有三种策略:忽略该组件,将其归零或添加最佳猜测或均匀随机噪声到所有时间步长。 针对数据含义,每种补救措施都有其优缺点。 通常情况下,忽略任何带有缺失值的组件是首选的,但这会偏向于将RMSE偏向零,使您认为性能已经提高,而实际上并没有。 如果存在大量缺失值,则添加最佳猜测的随机噪声可能更好。
为了保证RMSE输出的相对正确性,必须从输入中消除所有null / infinities。
RMSE对于不属于数据点的异常值具有零容忍度
均方根误差依赖于所有数据都正确且被视为平等,这意味着一个离群点会完全破坏整个计算。 为了处理异常值并在一定阈值后忽略其巨大影响,请参见内置阈值以去除异常值的鲁棒估计器。
fit1 <- lm(y ~ x1 + x2, data = Data),您可以使用y_hat <- fitted.values(fit1)提取拟合值。请尝试在提问时提供数据和代码。 - nrussell