我有一个np矩阵,我想将其转换为一个3D数组,并使用元素的one-hot编码作为第三个维度。有没有一种方法可以在不循环遍历每一行的情况下完成?
a=[[1,3],
[2,4]]
应该制成
b=[[1,0,0,0], [0,0,1,0],
[0,1,0,0], [0,0,0,1]]
我有一个np矩阵,我想将其转换为一个3D数组,并使用元素的one-hot编码作为第三个维度。有没有一种方法可以在不循环遍历每一行的情况下完成?
a=[[1,3],
[2,4]]
应该制成
b=[[1,0,0,0], [0,0,1,0],
[0,1,0,0], [0,0,0,1]]
这里有一个顽皮的一行代码,它滥用了广播比较-
(np.arange(a.max()) == a[...,None]-1).astype(int)
运行示例:
In [120]: a
Out[120]:
array([[1, 7, 5, 3],
[2, 4, 1, 4]])
In [121]: (np.arange(a.max()) == a[...,None]-1).astype(int)
Out[121]:
array([[[1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 0, 0]],
[[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0]]])
对于 以0为基准 的索引,应该是 -
In [122]: (np.arange(a.max()+1) == a[...,None]).astype(int)
Out[122]:
array([[[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0]],
[[0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0]]])
In [223]: a
Out[223]:
array([[ 6, 12, 10, 8],
[ 7, 9, 6, 9]])
In [224]: a_off = a - a.min() # feed a_off to proposed approaches
In [225]: (np.arange(a_off.max()+1) == a_off[...,None]).astype(int)
Out[225]:
array([[[1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 0, 0]],
[[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0]]])
如果您可以接受一个布尔数组,其中1's为True,0's为False,则可以跳过.astype(int)转换。
我们还可以初始化一个全零数组,并使用高级索引来索引输出。因此,对于基于 0 的索引,我们将有 -
def onehot_initialization(a):
ncols = a.max()+1
out = np.zeros(a.shape + (ncols,), dtype=int)
out[all_idx(a, axis=2)] = 1
return out
辅助函数 -
# https://dev59.com/_FYO5IYBdhLWcg3wP_Ub#46103129/ @Divakar
def all_idx(idx, axis):
grid = np.ogrid[tuple(map(slice, idx.shape))]
grid.insert(axis, idx)
return tuple(grid)
当处理更大范围的值时,这应该会更加高效。
对于基于1的索引,只需将a-1作为输入即可。
现在,如果您想要输出稀疏数组,并且据我所知,由于scipy内置的稀疏矩阵仅支持2D格式,因此您可以获得一个稀疏输出,它是早期输出的重塑版本,其中前两个轴合并并保留第三个轴不变。 对于基于0的索引,实现��下所示-
from scipy.sparse import coo_matrix
def onehot_sparse(a):
N = a.size
L = a.max()+1
data = np.ones(N,dtype=int)
return coo_matrix((data,(np.arange(N),a.ravel())), shape=(N,L))
再次强调,对于采用 1-based 索引的情况,只需将 a-1 作为输入即可。
示例运行 -
In [157]: a
Out[157]:
array([[1, 7, 5, 3],
[2, 4, 1, 4]])
In [158]: onehot_sparse(a).toarray()
Out[158]:
array([[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0]])
In [159]: onehot_sparse(a-1).toarray()
Out[159]:
array([[1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0]])
如果您可以接受输出稀疏,那么这种方法将比之前两种方法更好。
基于0的索引运行时间比较
情况#1:
In [160]: a = np.random.randint(0,100,(100,100))
In [161]: %timeit (np.arange(a.max()+1) == a[...,None]).astype(int)
1000 loops, best of 3: 1.51 ms per loop
In [162]: %timeit onehot_initialization(a)
1000 loops, best of 3: 478 µs per loop
In [163]: %timeit onehot_sparse(a)
10000 loops, best of 3: 87.5 µs per loop
In [164]: %timeit onehot_sparse(a).toarray()
1000 loops, best of 3: 530 µs per loop
第二案例:
In [166]: a = np.random.randint(0,500,(100,100))
In [167]: %timeit (np.arange(a.max()+1) == a[...,None]).astype(int)
100 loops, best of 3: 8.51 ms per loop
In [168]: %timeit onehot_initialization(a)
100 loops, best of 3: 2.52 ms per loop
In [169]: %timeit onehot_sparse(a)
10000 loops, best of 3: 87.1 µs per loop
In [170]: %timeit onehot_sparse(a).toarray()
100 loops, best of 3: 2.67 ms per loop
为了发挥最佳性能,我们可以修改第二种方法,使用2D形状的输出数组进行索引,并且使用uint8数据类型以提高内存效率,从而实现更快的赋值,如下所示 -
def onehot_initialization_v2(a):
ncols = a.max()+1
out = np.zeros( (a.size,ncols), dtype=np.uint8)
out[np.arange(a.size),a.ravel()] = 1
out.shape = a.shape + (ncols,)
return out
时间 -
In [178]: a = np.random.randint(0,100,(100,100))
In [179]: %timeit onehot_initialization(a)
...: %timeit onehot_initialization_v2(a)
...:
1000 loops, best of 3: 474 µs per loop
10000 loops, best of 3: 128 µs per loop
In [180]: a = np.random.randint(0,500,(100,100))
In [181]: %timeit onehot_initialization(a)
...: %timeit onehot_initialization_v2(a)
...:
100 loops, best of 3: 2.38 ms per loop
1000 loops, best of 3: 213 µs per loop
tensorflow 或 keras),则可以使用来自https://www.tensorflow.org/api_docs/python/tf/keras/backend/one_hot或https://www.tensorflow.org/api_docs/python/tf/one_hot的one_hot函数。我正在使用这个方法,对于高维数据效果很好。>>> import tensorflow as tf
>>> tf.one_hot([[0,2],[1,3]], 4).numpy()
array([[[1., 0., 0., 0.],
[0., 0., 1., 0.]],
[[0., 1., 0., 0.],
[0., 0., 0., 1.]]], dtype=float32)
编辑:我刚意识到我的回答已经在被接受的答案中提到了。不幸的是,作为一个未注册的用户,我无法再删除它。
作为被接受的答案的补充:如果您只需要编码很少的类,并且可以接受np.bool数组作为输出,我发现以下方法甚至更快:
def onehot_initialization_v3(a):
ncols = a.max() + 1
labels_one_hot = (a.ravel()[np.newaxis] == np.arange(ncols)[:, np.newaxis]).T
labels_one_hot.shape = a.shape + (ncols,)
return labels_one_hot
时间安排(共10节课):
a = np.random.randint(0,10,(100,100))
assert np.all(onehot_initialization_v2(a) == onehot_initialization_v3(a))
%timeit onehot_initialization_v2(a)
%timeit onehot_initialization_v3(a)
# 102 µs ± 1.66 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
# 79.3 µs ± 815 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
然而,如果类别数量增加(现在有100个类别),情况会发生变化:
a = np.random.randint(0,100,(100,100))
assert np.all(onehot_initialization_v2(a) == one_hot_initialization_v3(a))
%timeit onehot_initialization_v2(a)
%timeit onehot_initialization_v3(a)
# 132 µs ± 1.4 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
# 639 µs ± 3.12 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
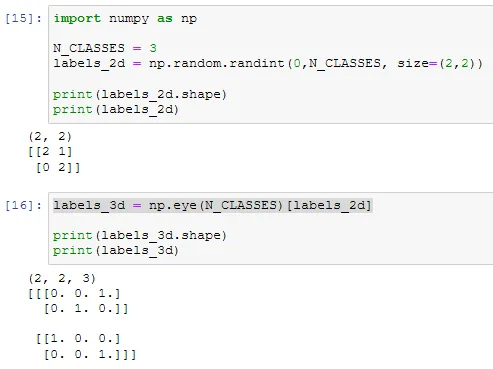
labels_3d = np.eye(N_CLASSES)[labels_2d]
a = (np.random.rand(40) > 0.5).astype(int).reshape(5, 8)
print(a)
>>> array([
[1, 0, 1, 1, 0, 1, 1, 0],
[0, 1, 1, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 1, 1, 1],
[1, 0, 1, 1, 0, 0, 0, 0]])
onehot = np.zeros((5, 8, 2))
x = np.arange(5).reshape(5, 1)
y = np.arange(8).reshape(1, 8)
onehot[x, y, a] = 1.
(x[i, j], y[i, j], a[i, j])给出,额外的坐标使用广播版本进行解释。x[i, j]就是i,y[i, j]就是j。因此,我们实际上是在定位onehot[i, j, a[i, j]]。我们使用a作为最后一个坐标,即第i行第j列的onehot目标。换句话说,第(i, j)个命令是翻转与(i, j)对应的onehot数组中所需类别。
.astype(int),因为那会产生一个不必要的副本。 - Ericnp.int8可能会省略复制。 - Eric(np.arange(a.max()) == a[..., None]-1).astype(int)。 - jdehesa