数据: 数据
代码:
## Load the data
ifpricc = read.csv(file = "IFPRI_CCAgg2050.csv", heade=TRUE)
#-----------------------------------------------------------------------
# Plotting Kernel density distribution for the final yield impact data
#-----------------------------------------------------------------------
ifpricc.df = as.data.frame(ifpricc)
ifpricc_mlt.df = melt(ifpricc.df, id.vars=c("crop","codereg","reg","sres","gcm","scen"))
kernel = ggplot(data=subset(ifpricc_mlt.df, reg %in% c("Canada","United States","Oceania","OECD Europe","Eastern Europe","Former USSR") & gcm %in% c("CSIRO","MIROC","noCC")),
aes(x = value, y = ..density..))
kernel = kernel + geom_density(aes(fill = gcm), alpha=.4, subset = .(crop %in% c("WHET")),
position="identity", stat="density", size=0.75,
bw = "nrd0", adjust = 1.5,
kernel = c("gaussian"))
kernel = kernel + scale_fill_manual(name="GCM model",breaks=c("CSIRO","MIROC","noCC"), values=c("red","blue","gray80"))
kernel = kernel + facet_grid(sres ~ reg, scale="free") + scale_y_continuous(breaks=seq(0,2,.25))
kernel = kernel + labs(title="Kernel density distribution - with and without climate change", y="Density", x="Yield") + theme_bw()
kernel = kernel + theme(plot.title=element_text(face="bold", size=rel(2), hjust=0.5, vjust=1.5, family="serif"),
axis.text.x=element_text(color="black", size=rel(2), hjust=0.5, family="serif"),
axis.text.y=element_text(color="black", size=rel(2), hjust=1, family="serif"),
axis.title.x=element_text(face="bold", color="black", size=rel(1.6), hjust=0.5, vjust=0.2, family="serif"),
axis.title.y=element_text(face="bold", color="black", size=rel(1.6), hjust=0.5, vjust=0.2, family="serif"),
strip.text=element_text(face="bold", size=rel(1.5), family="serif"),
legend.text=element_text(face="bold", size=rel(1.25), family="serif"),
legend.title=element_text(face="bold", size=rel(1.45), family="serif"))
结果:
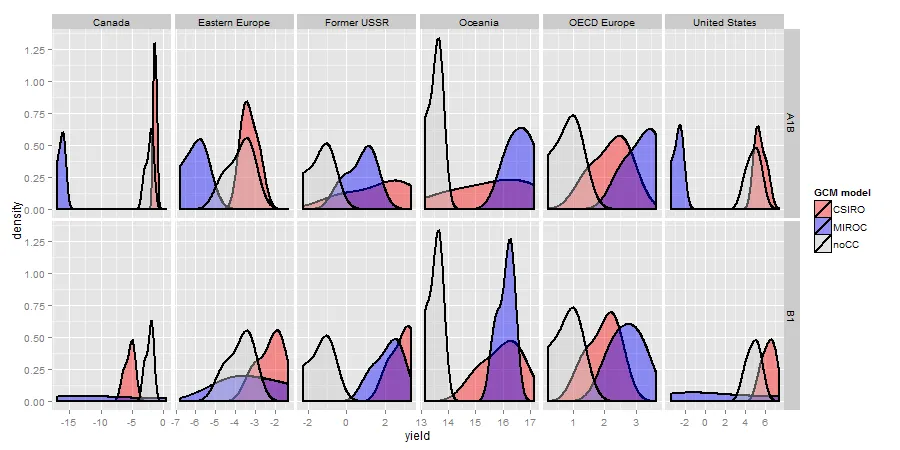
结果: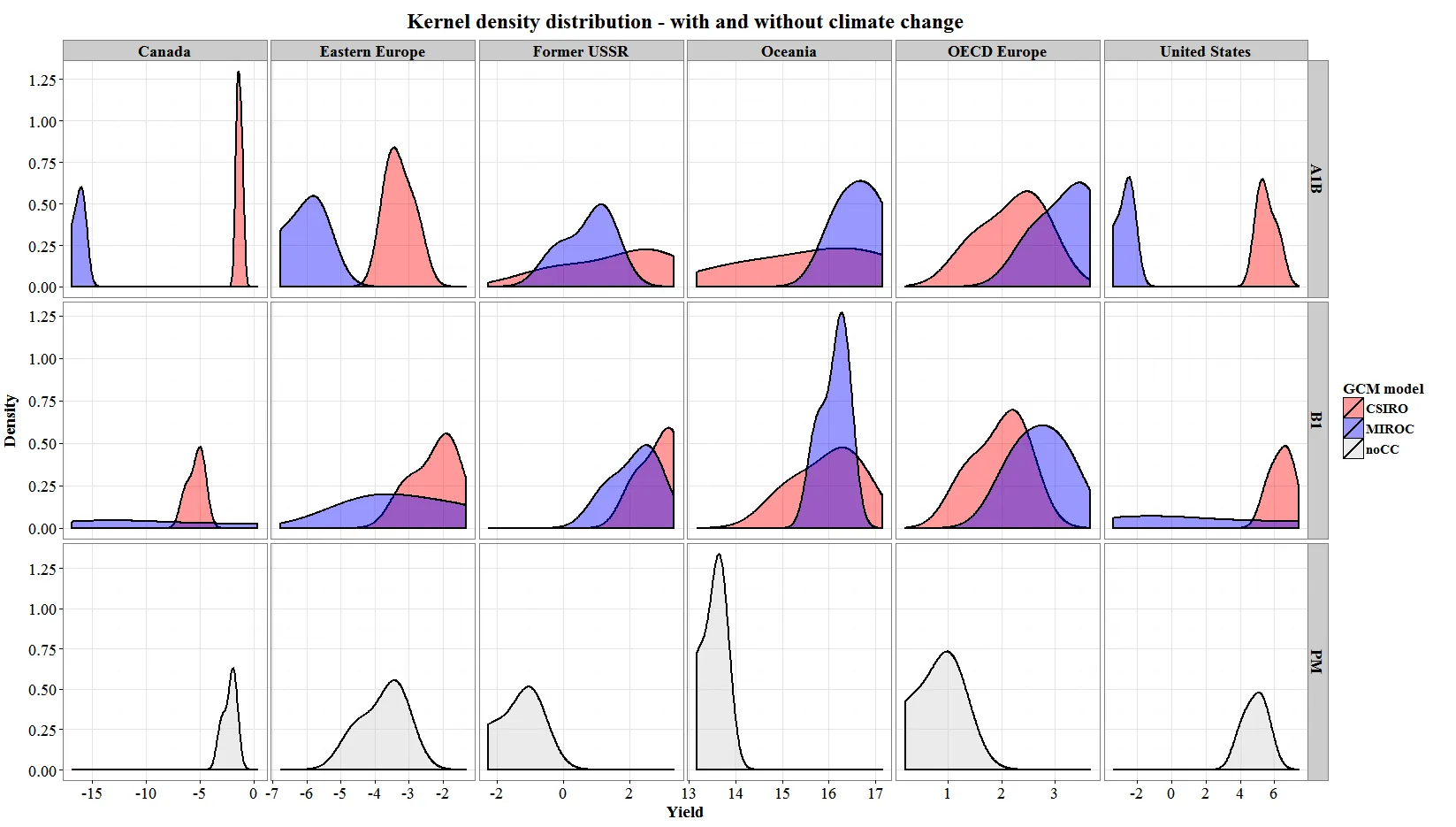
问题:
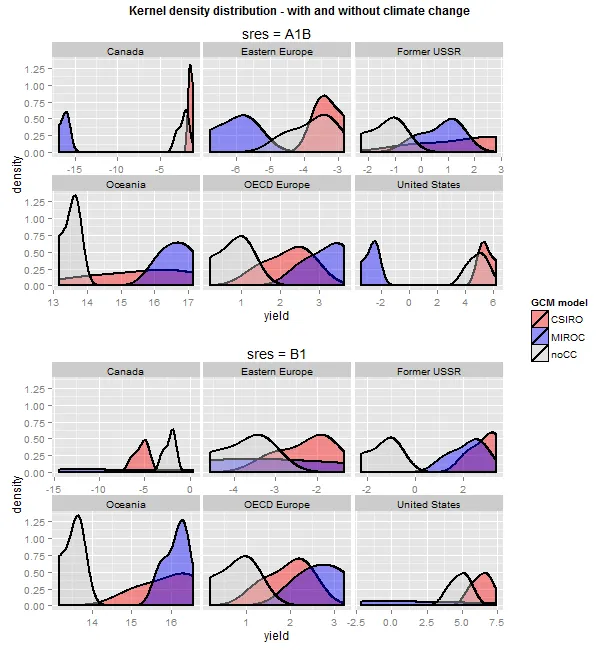
我在这里想要实现的是绘制核密度曲线。我的问题是,我想将基线核曲线(在较低的面板中)叠加在彩色曲线(两个上面的面板)上,并表示与基线的偏差。任何帮助都将不胜感激。
谢谢:)
备选问题:
因此,在查找网站上的潜在解决方案后,我进行了一些调整,得出了这个结果:不使用"sres" x "reg"通过facet_grid(sres ~ reg)分组,而是使用facet_wrap(~ reg)进行分组。它产生了更接近我所期望的结果 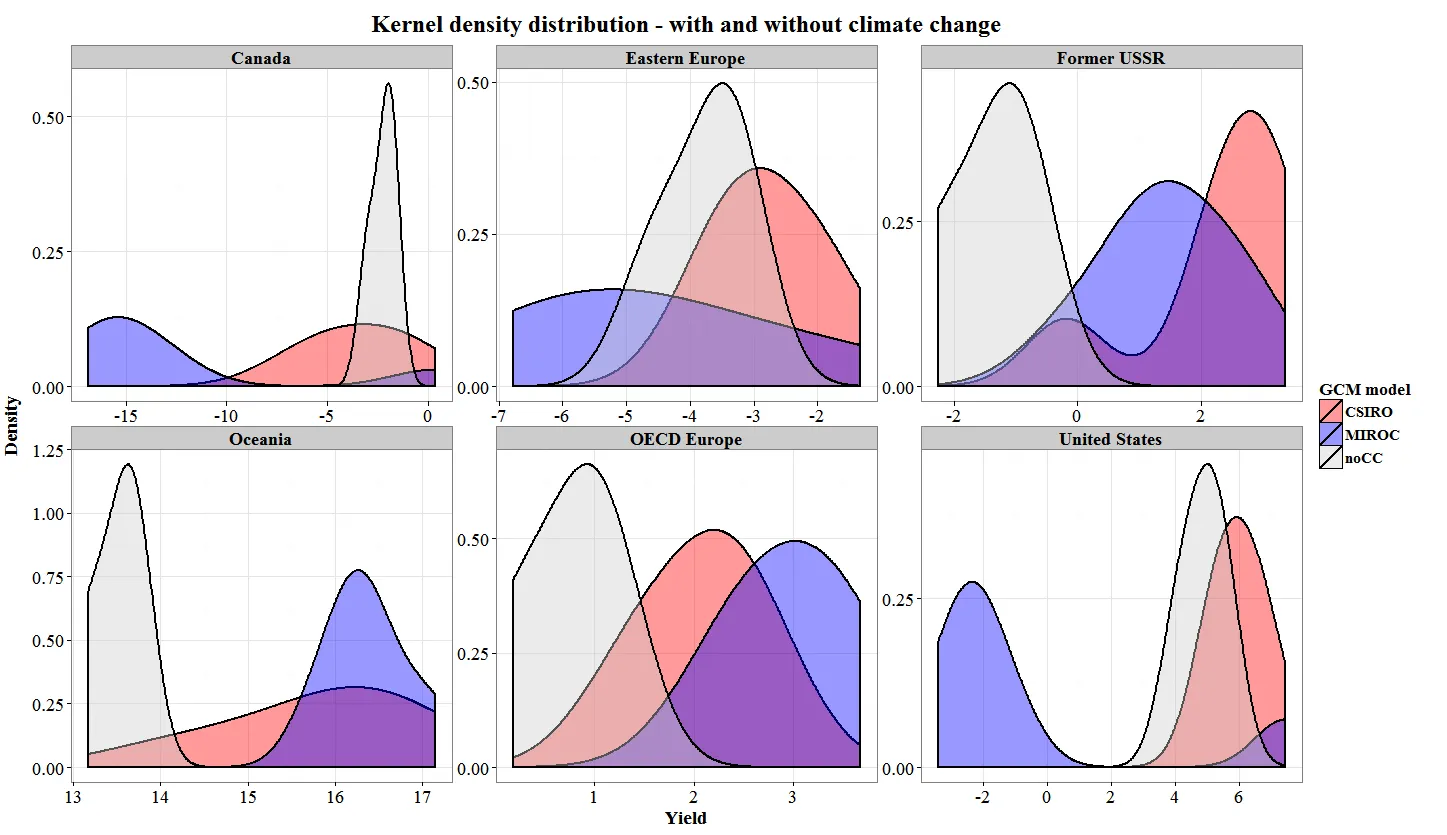 .
.
现在的问题是,我无法通过"sres"来识别分布,这正是我正在寻找的。为了解决这个问题,我想注释图表,通过添加垂直线来绘制数据的" sres "均值。但我有点不知道该怎么做。
有什么建议吗?