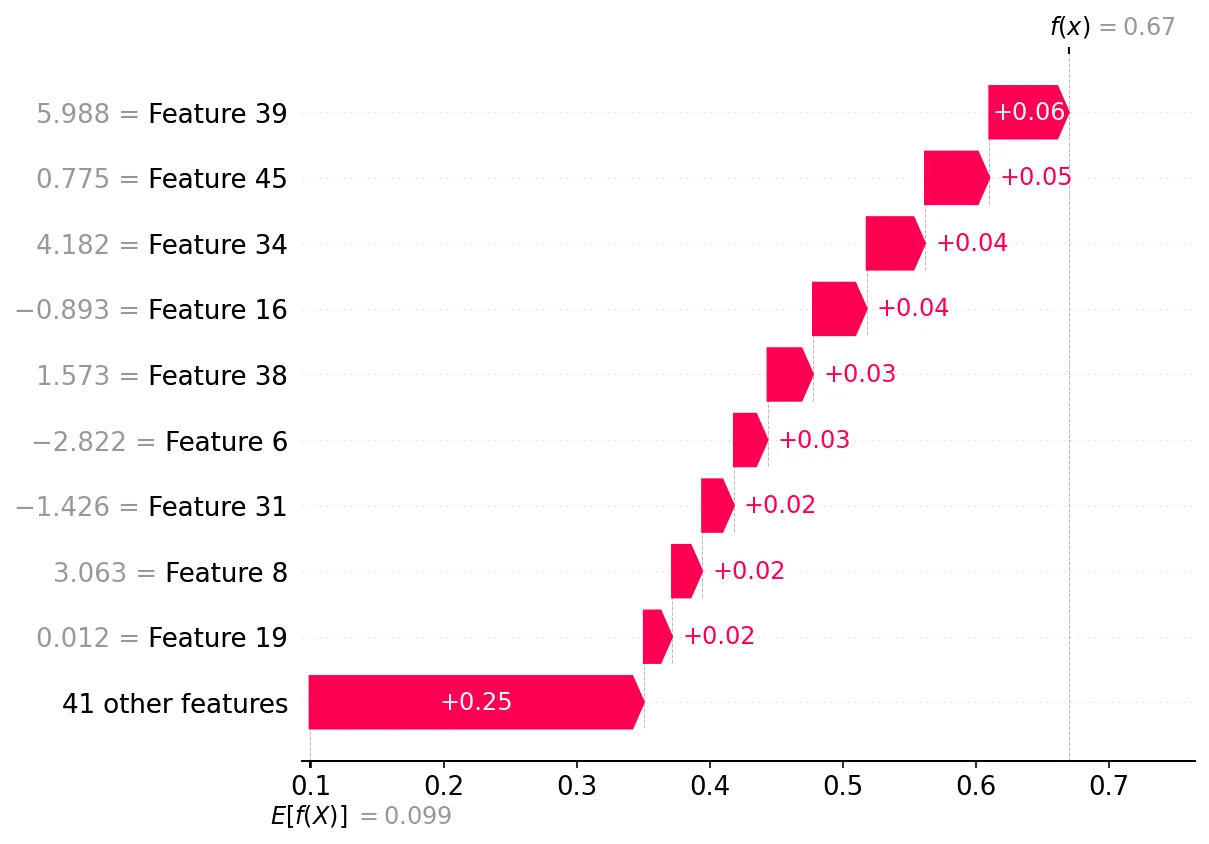
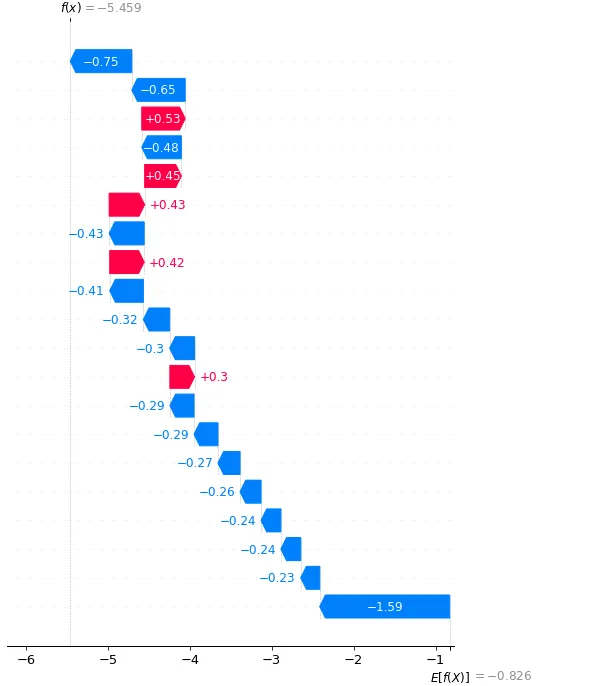
对于以下给出的代码,如果我只使用命令shap.plots.waterfall(shap_values[6]),将会报错:
'numpy.ndarray' 对象没有 'base_values' 属性
我必须先运行以下两个命令:
explainer2 = shap.Explainer(clf.best_estimator_.predict, X_train)
shap_values = explainer2(X_train)
然后运行waterfall命令以获取正确的绘图。以下是错误发生的示例:
from sklearn.datasets import make_classification
import seaborn as sns
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import pickle
import joblib
import warnings
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
f, (ax1,ax2) = plt.subplots(nrows=1, ncols=2,figsize=(20,8))
# Generate noisy Data
X_train,y_train = make_classification(n_samples=1000,
n_features=50,
n_informative=9,
n_redundant=0,
n_repeated=0,
n_classes=10,
n_clusters_per_class=1,
class_sep=9,
flip_y=0.2,
#weights=[0.5,0.5],
random_state=17)
X_test,y_test = make_classification(n_samples=500,
n_features=50,
n_informative=9,
n_redundant=0,
n_repeated=0,
n_classes=10,
n_clusters_per_class=1,
class_sep=9,
flip_y=0.2,
#weights=[0.5,0.5],
random_state=17)
model = RandomForestClassifier()
parameter_space = {
'n_estimators': [10,50,100],
'criterion': ['gini', 'entropy'],
'max_depth': np.linspace(10,50,11),
}
clf = GridSearchCV(model, parameter_space, cv = 5, scoring = "accuracy", verbose = True) # model
my_model = clf.fit(X_train,y_train)
print(f'Best Parameters: {clf.best_params_}')
# save the model to disk
filename = f'Testt-RF.sav'
pickle.dump(clf, open(filename, 'wb'))
explainer = Explainer(clf.best_estimator_)
shap_values_tr1 = explainer.shap_values(X_train)
shap.plots.waterfall(shap_values[6])
你能告诉我生成shap.plots.waterfall的正确步骤,以查看train数据吗?
谢谢!