我正在尝试使用SHAP对我的产品分类模型进行一些坏案例分析。我的数据看起来像这样:
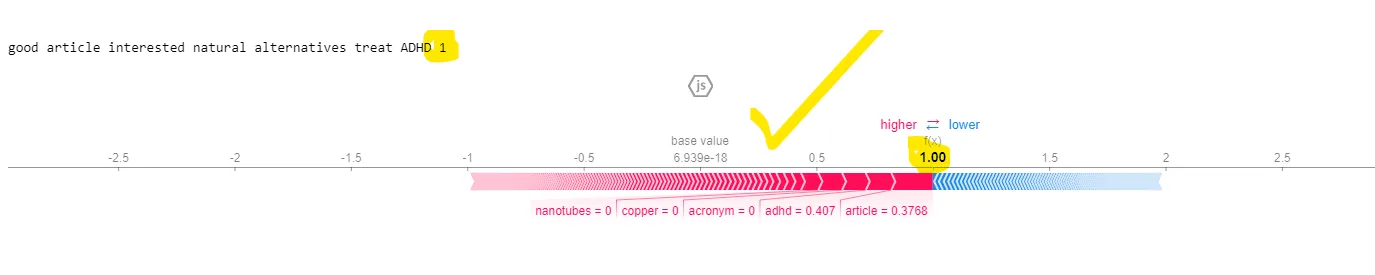
现在为了节省空间,我没有包含实际的摘要情节,但看起来还不错。我的问题是,我希望能够分析单个预测,并获得更接近以下内容的结果:
corpus_train, corpus_test, y_train, y_test = train_test_split(data['Name_Description'],
data['Category_Target'],
test_size = 0.2,
random_state=8)
vectorizer = TfidfVectorizer(stop_words='english', ngram_range=(1, 3), min_df=3, analyzer='word')
X_train = vectorizer.fit_transform(corpus_train)
X_test = vectorizer.transform(corpus_test)
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
X_train_sample = shap.sample(X_train, 100)
X_test_sample = shap.sample(X_test, 20)
masker = shap.maskers.Independent(data=X_test_sample)
explainer = shap.LinearExplainer(model, masker=masker)
shap_values = explainer.shap_values(X_test_sample)
X_test_array = X_test_sample.toarray()
shap.summary_plot(shap_values, X_test_array, feature_names=vectorizer.get_feature_names(), class_names=data['Category'].unique())
现在为了节省空间,我没有包含实际的摘要情节,但看起来还不错。我的问题是,我希望能够分析单个预测,并获得更接近以下内容的结果:
AttributeError: 'numpy.ndarray' object has no attribute 'output_names'
我仍然对shap_values的索引感到困惑。我该如何解决这个问题?