我正在尝试展开一个看起来像这样的JSON文件:
{
"teams": [
{
"teamname": "1",
"members": [
{
"firstname": "John",
"lastname": "Doe",
"orgname": "Anon",
"phone": "916-555-1234",
"mobile": "",
"email": "john.doe@wildlife.net"
},
{
"firstname": "Jane",
"lastname": "Doe",
"orgname": "Anon",
"phone": "916-555-4321",
"mobile": "916-555-7890",
"email": "jane.doe@wildlife.net"
}
]
},
{
"teamname": "2",
"members": [
{
"firstname": "Mickey",
"lastname": "Moose",
"orgname": "Moosers",
"phone": "916-555-0000",
"mobile": "916-555-1111",
"email": "mickey.moose@wildlife.net"
},
{
"firstname": "Minny",
"lastname": "Moose",
"orgname": "Moosers",
"phone": "916-555-2222",
"mobile": "",
"email": "minny.moose@wildlife.net"
}
]
}
]
}
我希望能将这个导出为Excel表格。 我目前的代码是这样的:
from pandas.io.json import json_normalize
import json
import pandas as pd
inputFile = 'E:\\teams.json'
outputFile = 'E:\\teams.xlsx'
f = open(inputFile)
data = json.load(f)
f.close()
df = pd.DataFrame(data)
result1 = json_normalize(data, 'teams' )
print result1
产生这个输出的结果:
members teamname
0 [{u'firstname': u'John', u'phone': u'916-555-... 1
1 [{u'firstname': u'Mickey', u'phone': u'916-555-... 2
每行中嵌套了2个成员的数据。我想要一个输出表格,显示所有4个成员的数据以及他们所属的团队名称。
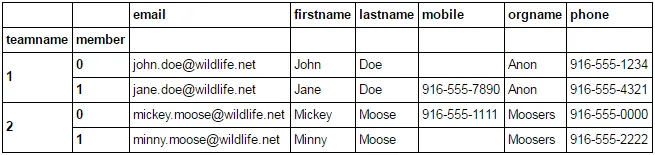

df.index.levels[0].name = 'teamname'这一行会返回以下错误:AttributeError: 'Int64Index' object has no attribute 'levels'。 - spainepd.concat分配给数据框df。 - piRSquared