我有以下代码,它将pandas数据框的一列值变为新数据框的列。 数据框的第一列中的值成为新数据框的索引。
在某种程度上,我想将邻接表转换为邻接矩阵。 到目前为止,这是代码:
在某种程度上,我想将邻接表转换为邻接矩阵。 到目前为止,这是代码:
import pandas as pa
# Create a dataframe
oldcols = {'col1':['a','a','b','b'], 'col2':['c','d','c','d'], 'col3':[1,2,3,4]}
a = pa.DataFrame(oldcols)
# The columns of the new data frame will be the values in col2 of the original
newcols = list(set(oldcols['col2']))
rows = list(set(oldcols['col1']))
# Create the new data matrix
data = np.zeros((len(rows), len(newcols)))
# Iterate over each row and fill in the new matrix
for row in zip(a['col1'], a['col2'], a['col3']):
rowindex = rows.index(row[0])
colindex = newcols.index(row[1])
data[rowindex][colindex] = row[2]
newf = pa.DataFrame(data)
newf.columns = newcols
newf.index = rows
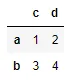
这个针对特定情况的方法如下:原始数据框
col1 col2 col3
0 a c 1
1 a d 2
2 b c 3
3 b d 4
被转化为一个新的类似于DataFrame的数据结构。
c d
a 1 2
b 3 4
如果col3中的值不是数字,它将失败。我的问题是,是否有更优雅/健壮的方法来解决这个问题?
aggfunc参数,允许您指定如何将重复值聚合为单个值。或者,在调用df.pivot之前,您可以删除重复项。 - unutbu