在绘制填充值的平均值之前,您应该先对值进行聚合。scale_colour_gradient(...)不是在数据层级上工作,而是在可视化层级上工作。让我们从一个玩具数据框开始构建一个可重复使用的示例。
mydata = expand.grid(bonus = seq(0, 1, 0.25), malus = seq(0, 1, 0.25), type = c("Risquophile","Moyen","Risquophobe"))
mydata = do.call("rbind",replicate(40, mydata, simplify = FALSE))
mydata$value= runif(nrow(mydata), min=0, max=50)
mydata$coop = "cooperative"
现在,在绘图之前,我建议您计算每组40个值的平均值,并且为此操作我喜欢使用dplyr包:
library(dplyr)
data = mydata %>% group_by("bonus","malus","type","coop") %>% summarise(vr=mean(value))
现在你已经准备好使用
ggplot2绘制数据集了:
library(ggplot2)
g = ggplot(data, aes(x=bonus,y=malus,fill=vr))
g = g + geom_tile()
g = g + facet_grid(type~coop)
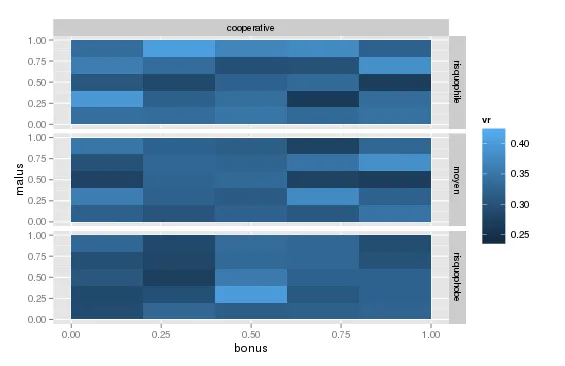
这是结果:
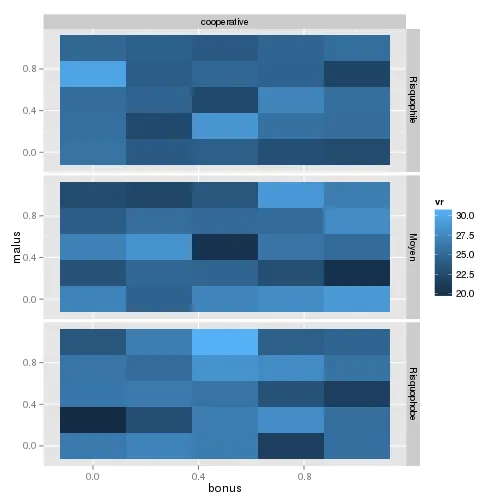
你可以确保填充值正好是你的值的平均值。
这是否符合你的预期?
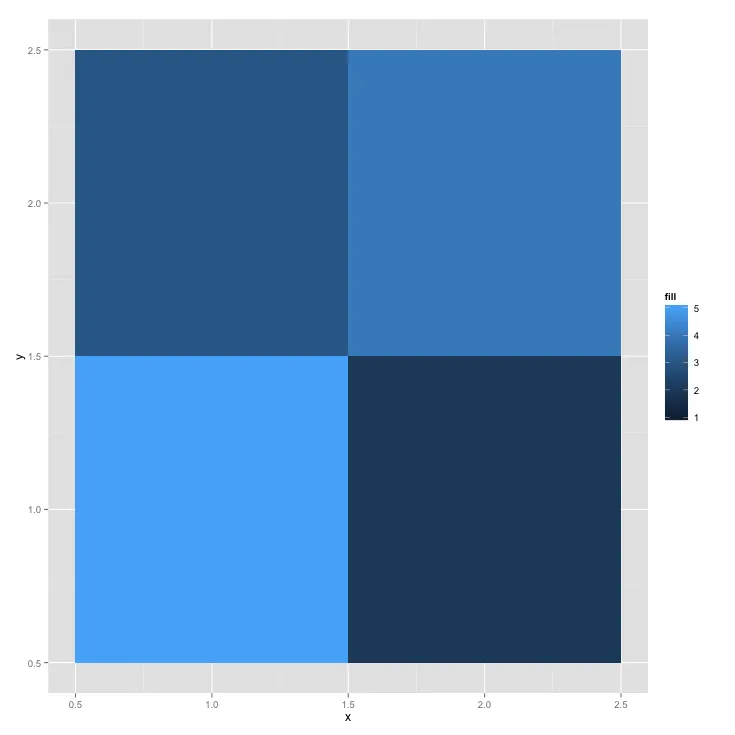
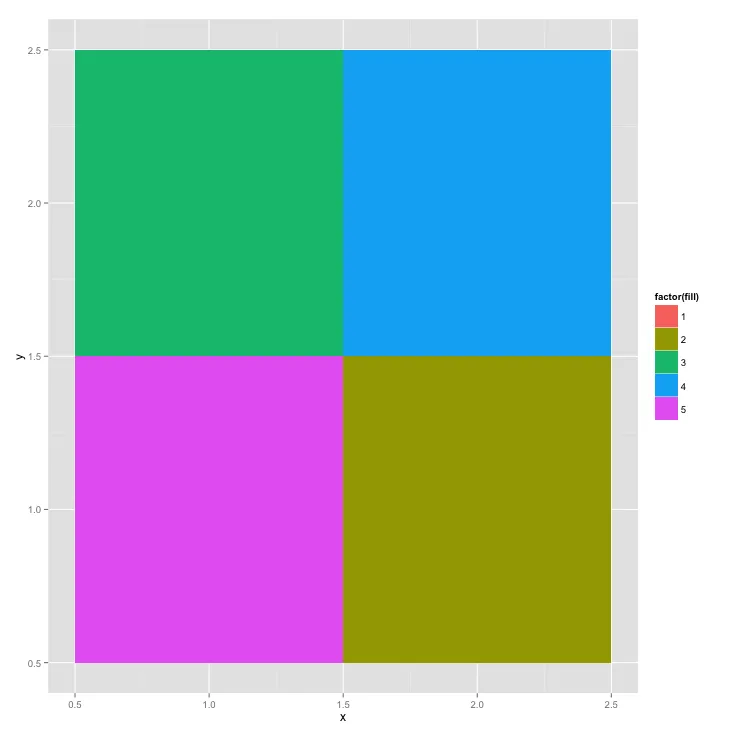
aggregate()函数,我找到了一个解决方案!如果能在ggplot2中实现这种统计解决方案就太棒了。 - delaye