5个回答
25
以下是使用XlsxWriter的一种方法:
import pandas as pd
# Create a Pandas dataframe from some data.
data = [10, 20, 30, 40, 50, 60, 70, 80]
df = pd.DataFrame({'Rank': data,
'Country': data,
'Population': data,
'Data1': data,
'Data2': data})
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter("pandas_table.xlsx", engine='xlsxwriter')
# Convert the dataframe to an XlsxWriter Excel object. Turn off the default
# header and index and skip one row to allow us to insert a user defined
# header.
df.to_excel(writer, sheet_name='Sheet1', startrow=1, header=False, index=False)
# Get the xlsxwriter workbook and worksheet objects.
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# Get the dimensions of the dataframe.
(max_row, max_col) = df.shape
# Create a list of column headers, to use in add_table().
column_settings = []
for header in df.columns:
column_settings.append({'header': header})
# Add the table.
worksheet.add_table(0, 0, max_row, max_col - 1, {'columns': column_settings})
# Make the columns wider for clarity.
worksheet.set_column(0, max_col - 1, 12)
# Close the Pandas Excel writer and output the Excel file.
writer.save()
输出:
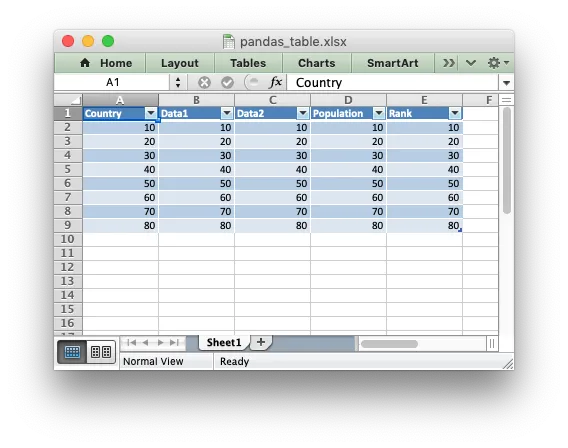
更新:我已经在XlsxWriter文档中添加了一个类似的示例:示例:带有工作表表格的Pandas Excel输出
- jmcnamara
1
我可能需要借鉴你写的一些内容。我更喜欢你提出标题的方式,而不是我采用的丑陋方法。 - Rob Bulmahn
7
使用to_excel无法完成此操作。一种解决方法是打开生成的xlsx文件,并使用openpyxl在其中添加表格:
import pandas as pd
df = pd.DataFrame({'Col1': [1,2,3], 'Col2': list('abc')})
filename = 'so58326392.xlsx'
sheetname = 'mySheet'
with pd.ExcelWriter(filename) as writer:
if not df.index.name:
df.index.name = 'Index'
df.to_excel(writer, sheet_name=sheetname)
import openpyxl
wb = openpyxl.load_workbook(filename = filename)
tab = openpyxl.worksheet.table.Table(displayName="df", ref=f'A1:{openpyxl.utils.get_column_letter(df.shape[1])}{len(df)+1}')
wb[sheetname].add_table(tab)
wb.save(filename)
请注意,所有表头都必须是字符串。如果您有一个未命名的索引(这是规则),第一个单元格(A1)将为空,这将导致文件损坏。为避免出现这种情况,请给索引命名(如上所示),或使用以下方法导出不带索引的数据框:
df.to_excel(writer, sheet_name=sheetname, index=False)
- Stef
3
1Openpyxl文档关于与Pandas的使用:https://openpyxl.readthedocs.io/en/stable/pandas.html - supermitch
1请注意,此解决方案不适用于具有超过26个字符的数据框。您应该将
chr(len(df.columns) + 64) 替换为 openpyxl.utils.get_column_letter(df.shape[1])。 - Thrastylon@Thrastylon 非常感谢,我已经更新了答案(之前不知道有
get_column_letter 这个函数)。 - Stef4
如果您不想保存、重新打开和重新保存文件,另一个解决方法是使用xlsxwriter。它可以直接写入ListObject表格,但不支持直接从数据框中写入,因此您需要拆分部件:
import pandas as pd
import xlsxwriter as xl
df = pd.DataFrame({'Col1': [1,2,3], 'Col2': list('abc')})
filename = 'output.xlsx'
sheetname = 'Table'
tablename = 'TEST'
(rows, cols) = df.shape
data = df.to_dict('split')['data']
headers = []
for col in df.columns:
headers.append({'header':col})
wb = xl.Workbook(filename)
ws = wb.add_worksheet()
ws.add_table(0, 0, rows, cols-1,
{'name': tablename
,'data': data
,'columns': headers})
wb.close()
add_table()函数需要'data'参数作为一个列表的列表,其中每个子列表表示数据框中的一行,'columns'参数作为表头的一个字典列表,每个列由形如{'header': 'ColumnName'}的字典指定。- Rob Bulmahn
3
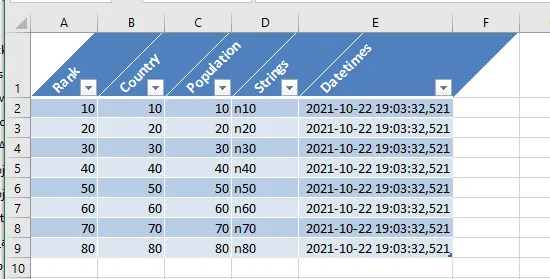
我创建了一个包来从 pandas 中编写格式正确的 Excel 表格:pandas-xlsx-tables。
你也可以使用
from pandas_xlsx_tables import df_to_xlsx_table
import pandas as pd
data = [10, 20, 30, 40, 50, 60, 70, 80]
df = pd.DataFrame({'Rank': data,
'Country': data,
'Population': data,
'Strings': [f"n{n}" for n in data],
'Datetimes': [pd.Timestamp.now() for _ in range(len(data))]})
df_to_xlsx_table(df, "my_table", index=False, header_orientation="diagonal")
你也可以使用
xlsx_table_to_df进行反向操作。
- Thijs D
1
很好... 有没有关于如何更新现有命名表的建议? - Ian Beyer
0
基于 @jmcnamara 的回答,但作为一个方便的函数并使用 "with" 语句:
import pandas as pd
def to_excel(df:pd.DataFrame, excel_name: str, sheet_name: str, startrow=1, startcol=0):
""" Exports pandas dataframe as a formated excel table """
with pd.ExcelWriter(excel_name, engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name=sheet_name, startrow=startrow, startcol=startcol, header=True, index=False)
workbook = writer.book
worksheet = writer.sheets[sheet_name]
max_row, max_col = df.shape
olumn_settings = [{'header': header} for header in df.columns]
worksheet.add_table(startrow, startcol, max_row+startrow, max_col+startcol-1, {'columns': column_settings})
# style columns
worksheet.set_column(startcol, max_col + startcol, 21)
- Ziur Olpa
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接