我正在尝试使用SciPy的“dendrogram”方法,根据阈值将我的数据划分为若干个簇。然而,一旦我创建了一个树状图并检索其“color_list”,该列表中的条目数比标签少一个。
另外,我尝试使用“fcluster”,并使用我在“dendrogram”中确定的相同阈值;然而,这并没有产生相同的结果——它只给了我一个簇,而不是三个。
以下是我的代码。
另外,我尝试使用“fcluster”,并使用我在“dendrogram”中确定的相同阈值;然而,这并没有产生相同的结果——它只给了我一个簇,而不是三个。
以下是我的代码。
import pandas
data = pandas.DataFrame({'total_runs': {0: 2.489857755536053,
1: 1.2877651950650333, 2: 0.8898850111727028, 3: 0.77750321282732704, 4: 0.72593099987615461, 5: 0.70064977003207007,
6: 0.68217502514600825, 7: 0.67963194285399975, 8: 0.64238326692987524, 9: 0.6102581538587678, 10: 0.52588765899448564,
11: 0.44813665774322564, 12: 0.30434031343774476, 13: 0.26151929543260161, 14: 0.18623657993534984, 15: 0.17494230269731209,
16: 0.14023670906519603, 17: 0.096817318756050832, 18: 0.085822227670014059, 19: 0.042178447746868117, 20: -0.073494398270518693,
21: -0.13699665903273103, 22: -0.13733324345373216, 23: -0.31112299949731331, 24: -0.42369178918768974, 25: -0.54826542322710636,
26: -0.56090603814914863, 27: -0.63252372328438811, 28: -0.68787316140457322, 29: -1.1981351436422796, 30: -1.944118415387774,
31: -2.1899746357945964, 32: -2.9077222144449961},
'total_salaries': {0: 3.5998991340231234,
1: 1.6158435140488829, 2: 0.87501176080187315, 3: 0.57584734201367749, 4: 0.54559862861592978, 5: 0.85178295446270169,
6: 0.18345463930386757, 7: 0.81380836410678736, 8: 0.43412670908952178, 9: 0.29560433676606418, 10: 1.0636736398252848,
11: 0.08930130612600648, 12: -0.20839133305170349, 13: 0.33676911316165403, 14: -0.12404710480916628, 15: 0.82454221267393346,
16: -0.34510456295395986, 17: -0.17162157282367937, 18: -0.064803261585569982, 19: -0.22807757277294818, 20: -0.61709008778669083,
21: -0.42506873158089231, 22: -0.42637946918743924, 23: -0.53516500398181921, 24: -0.68219830809296633, 25: -1.0051418692474947,
26: -1.0900316082184143, 27: -0.82421065378673986, 28: 0.095758053930450004, 29: -0.91540963929213015, 30: -1.3296449323844519,
31: -1.5512503530547552, 32: -1.6573856443389405}})
from scipy.spatial.distance import pdist
from scipy.cluster.hierarchy import linkage, dendrogram
distanceMatrix = pdist(data)
dend = dendrogram(linkage(distanceMatrix, method='complete'),
color_threshold=4,
leaf_font_size=10,
labels = df.teamID.tolist())
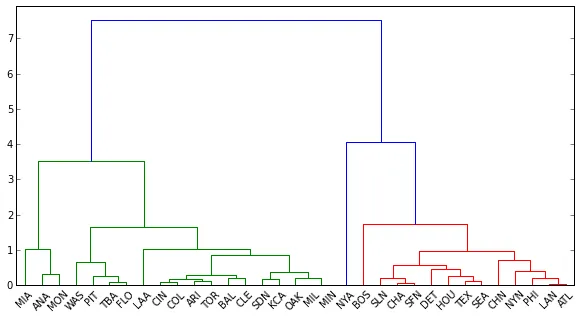
len(dend['color_list'])
Out[169]: 32
len(df.index)
Out[170]: 33
为什么dendrogram只对32个标签进行着色,即使数据中有33个观测值?这是我提取标签及其对应的簇(在上面以蓝色、绿色和红色着色)的方法吗?如果不是,那么如何正确地“剪枝”树?
这是我使用fcluster的尝试。当相同的阈值用于dend时返回三个簇,为什么它只返回一个集合?
from scipy.cluster.hierarchy import fcluster
fcluster(linkage(distanceMatrix, method='complete'), 4)
Out[175]:
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1], dtype=int32)
color_list的说明是:“颜色名称列表。第k个元素表示第k个链接的颜色。”参见:http://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.dendrogram.html。我认为这是一个误解。 - cel