给定以下2D数组:
a = np.array([
[1, 2, 3],
[2, 3, 4],
])
我想在第二个轴上添加一列零,以获得:
b = np.array([
[1, 2, 3, 0],
[2, 3, 4, 0],
])
: import numpy as np
: N = 3
: A = np.eye(N)
: np.c_[ A, np.ones(N) ] # add a column
array([[ 1., 0., 0., 1.],
[ 0., 1., 0., 1.],
[ 0., 0., 1., 1.]])
: np.c_[ np.ones(N), A, np.ones(N) ] # or two
array([[ 1., 1., 0., 0., 1.],
[ 1., 0., 1., 0., 1.],
[ 1., 0., 0., 1., 1.]])
: np.r_[ A, [A[1]] ] # add a row
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.],
[ 0., 1., 0.]])
: # not np.r_[ A, A[1] ]
: np.r_[ A[0], 1, 2, 3, A[1] ] # mix vecs and scalars
array([ 1., 0., 0., 1., 2., 3., 0., 1., 0.])
: np.r_[ A[0], [1, 2, 3], A[1] ] # lists
array([ 1., 0., 0., 1., 2., 3., 0., 1., 0.])
: np.r_[ A[0], (1, 2, 3), A[1] ] # tuples
array([ 1., 0., 0., 1., 2., 3., 0., 1., 0.])
: np.r_[ A[0], 1:4, A[1] ] # same, 1:4 == arange(1,4) == 1,2,3
array([ 1., 0., 0., 1., 2., 3., 0., 1., 0.])
1:4 转换为方括号中的切片对象。我认为一个更加直接且速度更快的解决方法是执行以下操作:
import numpy as np
N = 10
a = np.random.rand(N,N)
b = np.zeros((N,N+1))
b[:,:-1] = a
还有时间:
In [23]: N = 10
In [24]: a = np.random.rand(N,N)
In [25]: %timeit b = np.hstack((a,np.zeros((a.shape[0],1))))
10000 loops, best of 3: 19.6 us per loop
In [27]: %timeit b = np.zeros((a.shape[0],a.shape[1]+1)); b[:,:-1] = a
100000 loops, best of 3: 5.62 us per loop
a = np.random.rand((N,N))更改为a = np.random.rand(N,N)来尝试一下。 - hlin117numpy.append函数:>>> a = np.array([[1,2,3],[2,3,4]])
>>> a
array([[1, 2, 3],
[2, 3, 4]])
>>> z = np.zeros((2,1), dtype=int64)
>>> z
array([[0],
[0]])
>>> np.append(a, z, axis=1)
array([[1, 2, 3, 0],
[2, 3, 4, 0]])
使用 hstack 的一种方法是:
b = np.hstack((a, np.zeros((a.shape[0], 1), dtype=a.dtype)))
dtype 参数,它不是必要的,甚至是不允许的。虽然你的解决方案已经足够优雅,但如果需要频繁“添加”到数组中,请注意不要使用它。如果无法一次性创建整个数组并稍后填充它,则创建一个数组列表,然后一次性使用 hstack 连接所有数组。 - eumiro我也对这个问题很感兴趣,比较了一下速度。
numpy.c_[a, a]
numpy.stack([a, a]).T
numpy.vstack([a, a]).T
numpy.ascontiguousarray(numpy.stack([a, a]).T)
numpy.ascontiguousarray(numpy.vstack([a, a]).T)
numpy.column_stack([a, a])
numpy.concatenate([a[:,None], a[:,None]], axis=1)
numpy.concatenate([a[None], a[None]], axis=0).T
以下所有方法对于任何输入向量a都会执行相同的操作。增长a的时间如下:
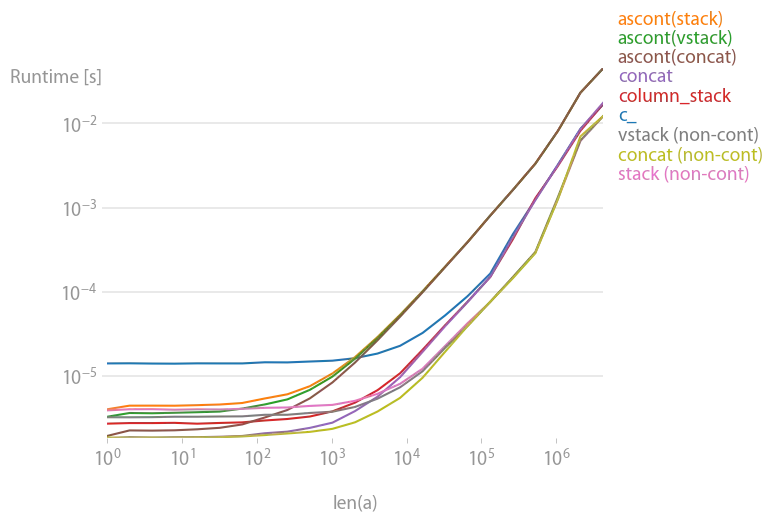
请注意,所有非连续变体(特别是stack/vstack)最终比所有连续变体更快。如果您需要连续性,则column_stack(因其清晰度和速度而言)似乎是一个不错的选择。
用于复制图的代码:
import numpy as np
import perfplot
b = perfplot.bench(
setup=np.random.rand,
kernels=[
lambda a: np.c_[a, a],
lambda a: np.ascontiguousarray(np.stack([a, a]).T),
lambda a: np.ascontiguousarray(np.vstack([a, a]).T),
lambda a: np.column_stack([a, a]),
lambda a: np.concatenate([a[:, None], a[:, None]], axis=1),
lambda a: np.ascontiguousarray(np.concatenate([a[None], a[None]], axis=0).T),
lambda a: np.stack([a, a]).T,
lambda a: np.vstack([a, a]).T,
lambda a: np.concatenate([a[None], a[None]], axis=0).T,
],
labels=[
"c_",
"ascont(stack)",
"ascont(vstack)",
"column_stack",
"concat",
"ascont(concat)",
"stack (non-cont)",
"vstack (non-cont)",
"concat (non-cont)",
],
n_range=[2 ** k for k in range(23)],
xlabel="len(a)",
)
b.save("out.png")
stack、hstack、vstack、column_stack、dstack等函数都是在np.concatenate函数之上构建的辅助函数。通过跟踪stack的定义,我发现np.stack([a,a])调用了np.concatenate([a[None], a[None]], axis=0)。将np.concatenate([a[None], a[None]], axis=0).T添加到perfplot中可能很好,以显示np.concatenate始终至少与其辅助函数一样快。 - unutbuc_ 和 column_stack。 - Confounded我认为以下内容非常优雅:
b = np.insert(a, 3, values=0, axis=1) # Insert values before column 3
b = np.insert(a, insert_index, values=a[:,2], axis=1)
这导致:
array([[1, 2, 3, 3],
[2, 3, 4, 4]])
就时间而言,insert 可能比JoshAdel的解决方案慢:
In [1]: N = 10
In [2]: a = np.random.rand(N,N)
In [3]: %timeit b = np.hstack((a, np.zeros((a.shape[0], 1))))
100000 loops, best of 3: 7.5 µs per loop
In [4]: %timeit b = np.zeros((a.shape[0], a.shape[1]+1)); b[:,:-1] = a
100000 loops, best of 3: 2.17 µs per loop
In [5]: %timeit b = np.insert(a, 3, values=0, axis=1)
100000 loops, best of 3: 10.2 µs per loop
insert(a, -1, ...) 来添加列。看来我只能将其放在最前面了。 - Thomas Ahlea.shape[axis]获取指定轴向上的大小来追加一行或一列。例如,若要追加一行,可以使用np.insert(a, a.shape[0], 999, axis=0)命令;若要追加一列,可以使用np.insert(a, a.shape[1], 999, axis=1)命令。请注意,不要改变原文的意思。 - blubberdiblub我认为:
np.column_stack((a, zeros(shape(a)[0])))
更加优美。
M 是一个形状为 (100,3) 的 ndarray,y 是一个形状为 (100,) 的 ndarray,则可以按照以下方式使用 append:M=numpy.append(M,y[:,None],1)
诀窍在于使用
y[:, None]
这将y转换为一个形状为(100, 1)的二维数组。
M.shape
现在提供
(100, 4)
Numpy的np.append方法有三个参数,前两个是2D numpy数组,第三个是轴参数,指示在哪个轴上附加:
import numpy as np
x = np.array([[1,2,3], [4,5,6]])
print("Original x:")
print(x)
y = np.array([[1], [1]])
print("Original y:")
print(y)
print("x appended to y on axis of 1:")
print(np.append(x, y, axis=1))
输出:
Original x:
[[1 2 3]
[4 5 6]]
Original y:
[[1]
[1]]
y appended to x on axis of 1:
[[1 2 3 1]
[4 5 6 1]]
np.concatenate 也可以使用
>>> a = np.array([[1,2,3],[2,3,4]])
>>> a
array([[1, 2, 3],
[2, 3, 4]])
>>> z = np.zeros((2,1))
>>> z
array([[ 0.],
[ 0.]])
>>> np.concatenate((a, z), axis=1)
array([[ 1., 2., 3., 0.],
[ 2., 3., 4., 0.]])
np.concatenate似乎比np.hstack快3倍。在我的实验中,np.concatenate也比手动将矩阵复制到空矩阵中略微快一些。这与Nico Schlömer在下面的回答一致。 - Lenar Hoyt
np.c_[*iterable];请参见expression-lists。 - denis