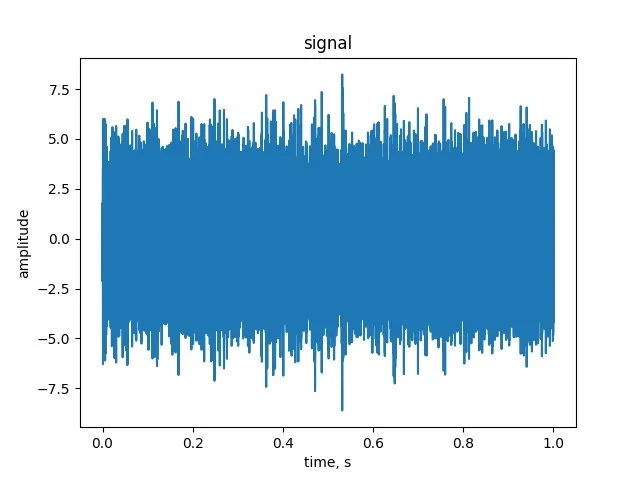
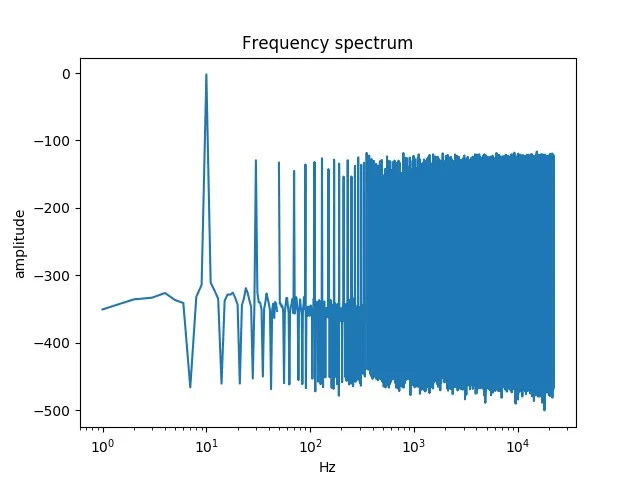
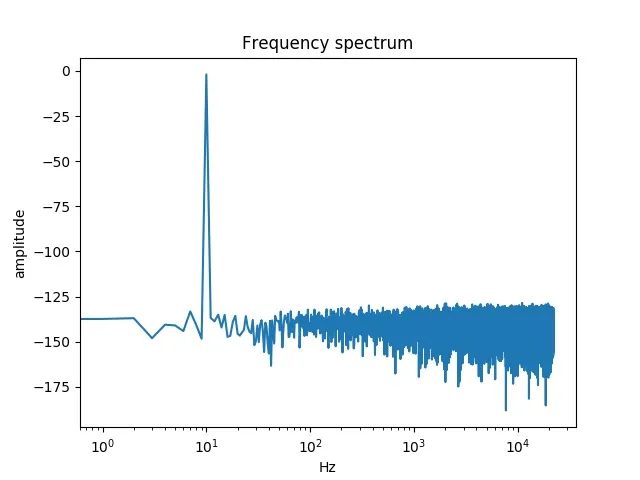
我使用Audacity生成了一个采样率为48KHz、持续时间为1秒的10Hz音调。然后,使用以下脚本加载它以绘制FFT图形:
from scipy.io import wavfile
from scipy.fftpack import fft, fftfreq
import matplotlib.pyplot as plt
from pydub import AudioSegment
import numpy as np
wav_filename = "\\test\\10Hz.wav"
samplerate, data = wavfile.read(wav_filename)
total_samples = len(data)
limit = int((total_samples /2)-1)
fft_abs = abs(fft(data))*2/total_samples
fft_db = 20*np.log10(fft_abs/32760)
freqs = fftfreq(total_samples,1/samplerate)
# plot the frequencies
plt.plot(freqs[:limit], fft_db[:limit])
plt.xscale('log',basex=10)
plt.title("Frequency spectrum")
plt.xlabel('Hz')
plt.ylabel('amplitude')
plt.show()
我得到了下面这张嘈杂的图表:
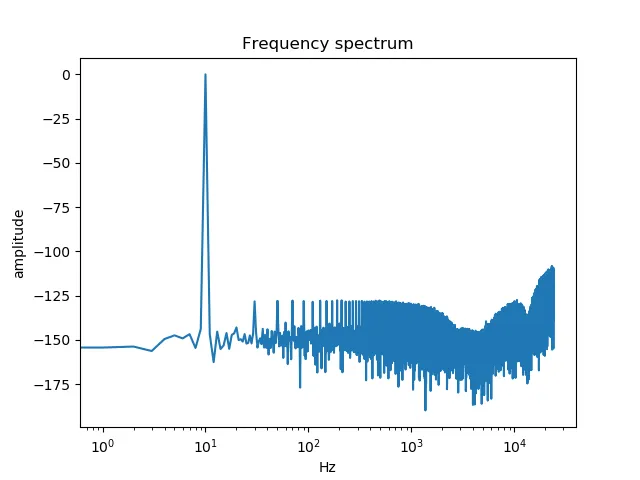 但是如果我使用Audacity查看频谱图,它就很好。
但是如果我使用Audacity查看频谱图,它就很好。我应该如何改进我的脚本以获得更好的FFT绘制?