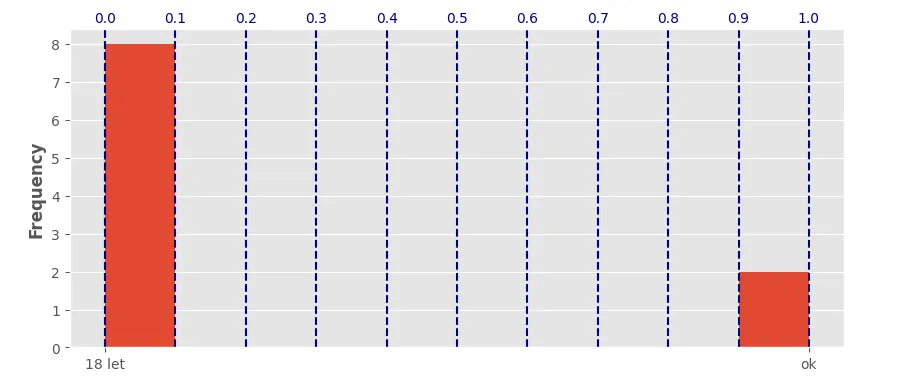
我有一个问题。 我需要在plt.hist()上将标签居中在X轴上。 我在这里找到了一些答案:如何在直方图图中居中标签,建议使用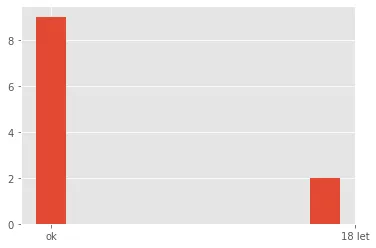
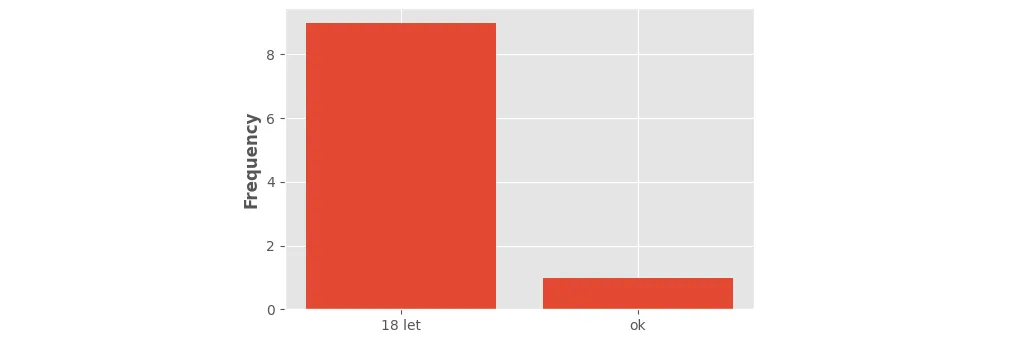
 我希望在每个条形图的中间精确地放置“ok”和“18 let”。请问如何解决?
我希望在每个条形图的中间精确地放置“ok”和“18 let”。请问如何解决?
整个代码:
align = "left / mid / right"。 然而,它并没有给我正确的输出:
plt.hist(data ['Col1'],align ='left')
plt.hist(data ['Col1'],align ='mid')
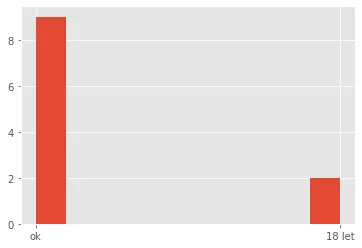
plt.hist(data ['Col1'],align ='right')
我希望在每个条形图的中间精确地放置“ok”和“18 let”。请问如何解决?整个代码:
plt.style.use('ggplot')
plt.xticks(rotation='vertical')
plt.locator_params(axis='y', integer=True)
plt.suptitle('My histogram', fontsize=14, fontweight='bold')
plt.ylabel('Frequency', fontweight='bold')
plt.hist(data['Col1'], align='mid')
plt.show()