背景:我有一组文档,每个文档都有两个相关联的概率值:属于A类的概率和属于B类的概率。这些类是互斥的,并且概率总和为1。例如,文档D具有(0.6,0.4)的概率,作为基本事实。
每个文档由包含的术语的tfidf表示,归一化为0到1。我还尝试了doc2vec(归一化形式为-1到1)和其他几种方法。
我构建了一个非常简单的神经网络来预测此概率分布。
- 输入层具有与特征相同的节点数
- 单个隐藏层具有一个节点
- 带softmax和两个节点的输出层
- 交叉熵损失函数
- 我还尝试使用不同的更新函数和学习速率
这是我使用nolearn编写的代码:
net = nolearn.lasagne.NeuralNet(
layers=[('input', layers.InputLayer),
('hidden1', layers.DenseLayer),
('output', layers.DenseLayer)],
input_shape=(None, X_train.shape[1]),
hidden1_num_units=1,
output_num_units=2,
output_nonlinearity=lasagne.nonlinearities.softmax,
objective_loss_function=lasagne.objectives.binary_crossentropy,
max_epochs=50,
on_epoch_finished=[es.EarlyStopping(patience=5, gamma=0.0001)],
regression=True,
update=lasagne.updates.adam,
update_learning_rate=0.001,
verbose=2)
net.fit(X_train, y_train)
y_true, y_pred = y_test, net.predict(X_test)
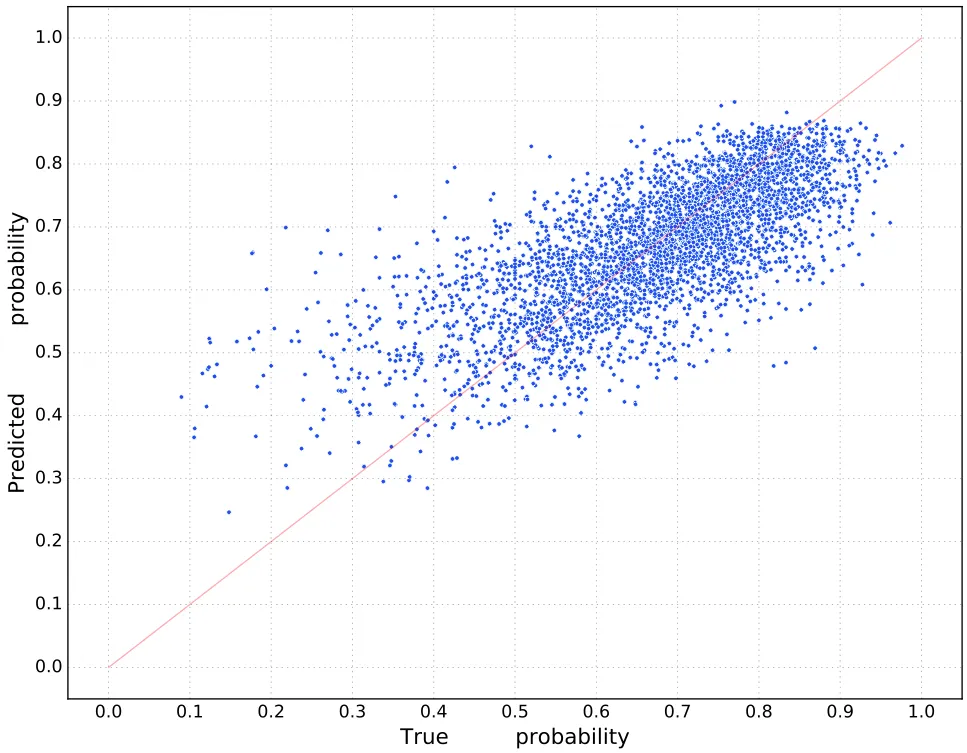
我的问题是:我的预测有一个截止点,没有一个预测会低于那个点(请查看图片以理解我的意思)。 这张图显示了真实概率和我的预测之间的差异。一个点越接近红线,预测就越好。理想情况下,所有点都应该在直线上。我该如何解决这个问题,为什么会出现这种情况? 编辑: 实际上,我通过简单地删除隐藏层来解决了这个问题。
{kind=link}
net = nolearn.lasagne.NeuralNet(
layers=[('input', layers.InputLayer),
('output', layers.DenseLayer)],
input_shape=(None, X_train.shape[1]),
output_num_units=2,
output_nonlinearity=lasagne.nonlinearities.softmax,
objective_loss_function=lasagne.objectives.binary_crossentropy,
max_epochs=50,
on_epoch_finished=[es.EarlyStopping(patience=5, gamma=0.0001)],
regression=True,
update=lasagne.updates.adam,
update_learning_rate=0.001,
verbose=2)
net.fit(X_train, y_train)
y_true, y_pred = y_test, net.predict(X_test)
但我仍然不明白为什么会出现这个问题,为什么移除隐藏层解决了它。有任何想法吗?
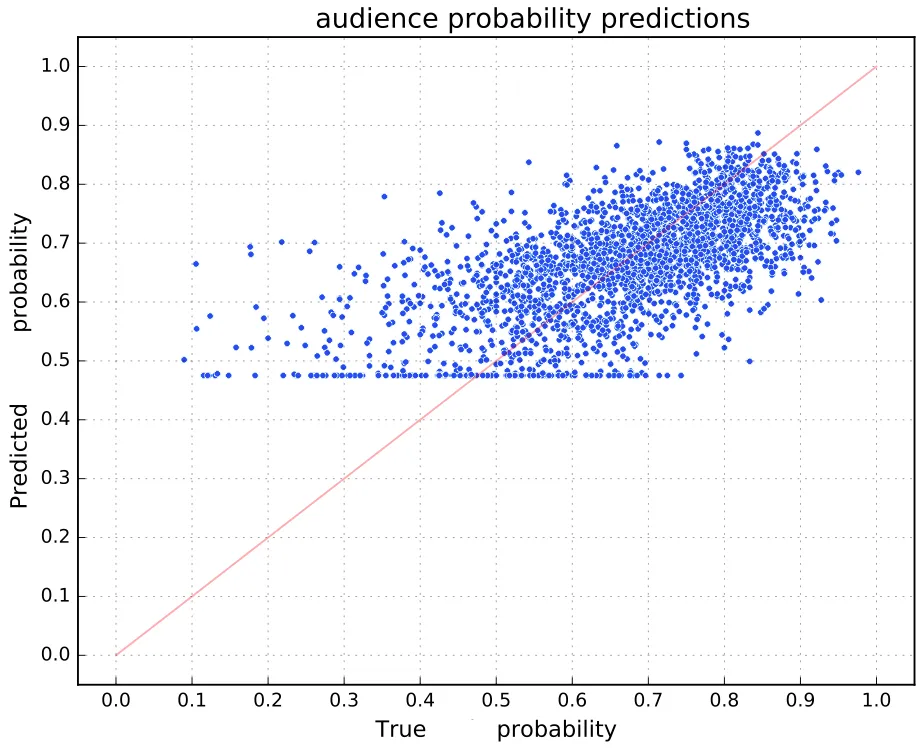
这是新的图表: