5. 常见的数组使用陷阱。
5.1 陷阱:信任不安全的类型链接。
好的,你已经被告知,或者自己发现,全局变量(可以在翻译单元之外访问的命名空间范围变量)是邪恶的™。但你知道它们有多邪恶™吗?考虑下面的程序,由两个文件[main.cpp]和[numbers.cpp]组成:
#include <iostream>
extern int* numbers;
int main()
{
using namespace std;
for( int i = 0; i < 42; ++i )
{
cout << (i > 0? ", " : "") << numbers[i];
}
cout << endl;
}
// [numbers.cpp]
int numbers[42] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
在Windows 7中,这个程序在MinGW g++ 4.4.1和Visual C++ 10.0下都可以编译和链接成功。
由于类型不匹配,当你运行程序时会导致程序崩溃。
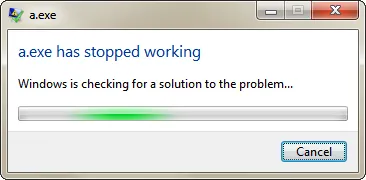
在非正式的解释中:程序存在未定义行为(UB),因此不会崩溃,而是可能会挂起,或者什么都不做,或者发送威胁性的电子邮件给美国、俄罗斯、印度、中国和瑞士的总统,并使鼻子里飞出鼻腔守护进程。
在实践中的解释:在main.cpp中,数组被视为指针,放置在与数组相同的地址上。对于32位可执行文件来说,这意味着数组中的第一个int值被视为指针。也就是说,在main.cpp中,numbers变量包含或看起来包含(int*)1。这导致程序访问地址空间底部的内存,这通常是保留和触发陷阱的。结果:程序崩溃。
编译器完全有权不诊断此错误,因为C++11 §3.5/10关于声明的兼容类型要求的规定如下:
[N3290 §3.5/10]
对于类型一致性规则的违反不需要诊断。
同一段落详细说明了允许的变化。
…声明一个数组对象的声明可以指定不同的数组类型,这些类型可以通过主要数组边界的存在或不存在来区分(8.3.4)。
这种允许的变化不包括在一个翻译单元中将名称声明为数组,在另一个翻译单元中将其声明为指针。
5.2陷阱:过早优化(memset和朋友)。
尚未编写。
5.3陷阱:使用C习惯用法获取元素数量。
有着深厚的C经验,编写以下代码是很自然的...
#define N_ITEMS( array ) (sizeof( array )/sizeof( array[0] ))
由于数组在需要时会衰变为指向第一个元素的指针,表达式`sizeof(a)/sizeof(a[0])`也可以写为`sizeof(a)/sizeof(*a)`。它的意思是相同的,无论如何写,这都是用于找到数组元素数量的C语言习惯用法。
主要陷阱:C语言习惯用法不具备类型安全性。例如,代码...
#include <stdio.h>
#define N_ITEMS( array ) (sizeof( array )/sizeof( *array ))
void display( int const a[7] )
{
int const n = N_ITEMS( a );
printf( "%d elements.\n", n );
}
int main()
{
int const moohaha[] = {1, 2, 3, 4, 5, 6, 7};
printf( "%d elements, calling display...\n", N_ITEMS( moohaha ) );
display( moohaha );
}
传递指向
N_ITEMS的指针,因此很可能会产生错误的结果。在Windows 7中编译为32位可执行文件时,会产生以下结果...
7个元素,调用display...
1个元素。
- 编译器将
int const a[7]重写为int const a[]。
- 编译器将
int const a[]重写为int const* a。
- 因此,
N_ITEMS被调用为指针。
- 对于32位可执行文件,
sizeof(array)(指针的大小)为4。
sizeof(*array)等同于sizeof(int),对于32位可执行文件也是4。
为了在运行时检测到这个错误,您可以进行以下操作...
#include <assert.h>
#include <typeinfo>
#define N_ITEMS( array ) ( \
assert(( \
"N_ITEMS requires an actual array as argument", \
typeid( array ) != typeid( &*array ) \
)), \
sizeof( array )/sizeof( *array ) \
)
7个元素,调用显示...
断言失败:(“N_ITEMS需要一个实际的数组作为参数”,文件runtime_detection.cpp,第16行)
此应用程序已请求运行时以异常方式终止。
请联系应用程序的支持团队获取更多信息。
运行时错误检测比没有检测要好,但会浪费一些处理器时间,也许还会浪费更多的程序员时间。最好在编译时进行检测!如果您愿意不支持C++98中的本地类型数组,那么可以这样做:
#include <stddef.h>
typedef ptrdiff_t Size;
template< class Type, Size n >
Size n_items( Type (&)[n] ) { return n; }
#define N_ITEMS( array ) n_items( array )
编译这个定义替换成第一个完整的程序,使用g++,我得到...
M:\count> g++ compile_time_detection.cpp
compile_time_detection.cpp: 在函数‘void display(const int*)’中:
compile_time_detection.cpp:14: 错误:没有为‘n_items(const int*&)’找到匹配的函数
M:\count> _
它的工作原理:数组以引用的方式传递给n_items,因此它不会衰变为指向第一个元素的指针,函数可以直接返回类型指定的元素数量。
在C++11中,您还可以将其用于本地类型的数组,并且这是一种类型安全的C++习惯用法,用于查找数组的元素数量。
5.4 C++11 - C++20陷阱:使用constexpr数组大小函数。
使用C++11及更高版本,实现数组大小函数的自然方式如下:
// Similar in C++03, but not constexpr.
template< class Type, std::size_t N >
constexpr std::size_t size( Type (&)[N] ) { return N
这将返回数组中元素的数量作为一个编译时常量。这个函数甚至在C++17中被标准化为
std::size。
例如,
size()可以用来声明一个与另一个数组相同大小的数组:
void foo()
{
int const x[] = {3, 1, 4, 1, 5, 9, 2, 6, 5, 4};
int y[ size(x) ] = {};
}
但是考虑一下使用
constexpr版本的代码:
template< class Collection >
void foo( Collection const& c )
{
constexpr int n = size( c );
}
int main()
{
int x[42];
foo( x );
}
陷阱:直到C++23,使用引用 c 在常量表达式中是不允许的,而且
所有主要编译器都会拒绝这段代码。根据
C++20标准,[expr.const] p5.12:
除非根据抽象机器的规则,表达式E的评估会导致以下情况之一,否则表达式E是一个核心常量表达式:
- [...]
- 引用类型的变量或数据成员的标识表达式,除非引用具有前置初始化并且满足以下条件之一:
- 它可用于常量表达式,或者
- 它的生命周期始于E的评估内;
c在常量表达式中既不可用,也没有在constexpr int n = ...中开始其生命周期,因此评估c不是核心常量表达式。这些限制在C++23中已被取消,参见P2280: 在常量表达式中使用未知指针和引用。c被视为对未指定对象的引用绑定([expr.const] p8)。
5.4.1 解决方法:与C++20兼容的constexpr大小函数
std::extent< decltype( c ) >::value;不是一个可行的解决方法,因为如果Collection不是一个数组,它将失败。
处理可能不是数组的集合时,需要使用一个可以重载的
size函数,但是为了编译时使用,还需要一个数组大小的编译时表示。经典的C++03解决方案,在C++11和C++14中也适用,就是让函数通过其函数结果
类型而不是值来报告其结果。例如像这样:
#include <array>
#include <cstddef>
template< class Type, std::size_t N >
auto static_n_items( Type (&)[N] )
-> char(&)[N];
template< class Type, std::size_t N >
auto static_n_items( std::array<Type, N> const& )
-> char(&)[N];
#define STATIC_N_ITEMS( c ) ( sizeof( static_n_items( c )) )
template< class Collection >
void foo( Collection const& c )
{
constexpr std::size_t n = STATIC_N_ITEMS( c );
}
int main()
{
int x[42];
std::array<int, 43> y;
foo( x );
foo( y );
}
关于选择
static_n_items的返回类型:这段代码没有使用
std::integral_constant,因为使用
std::integral_constant会直接将结果表示为
constexpr值,从而重新引入原始问题。
关于命名:解决
constexpr无效的引用问题的一部分解决方案是明确选择编译时常量。
直到C++23,像上面的
STATIC_N_ITEMS这样的宏可以实现可移植性,例如对于clang和Visual C++编译器,保留类型安全性。
相关:宏不遵守作用域,因此为了避免名称冲突,使用名称前缀(例如
MYLIB_STATIC_N_ITEMS)是一个好主意。
std::array、std::vector和gsl::span的共同可用性,我坦率地希望在如何在C++中使用数组的常见问题解答中说:“到现在为止,你可以开始考虑根本不使用它们。” - einpoklum