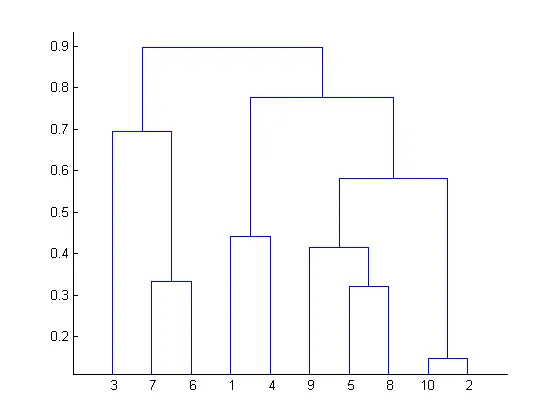
树状图是一种与层次聚类算法一起使用的数据结构,将不同“高度”的群集分组到树的不同分支中 - 高度对应于群集之间的距离度量。
在从某个输入数据集创建树状图之后,通常需要进一步解决如何“切割”树状图的问题,即选择一个高度,使得只有低于该高度的群集被认为是有意义的。
并不总是清楚在什么高度上切割树状图,但是存在一些算法,例如DynamicTreeCut算法,尝试从树状图中编程选择有意义的群集。
参见:
https://stats.stackexchange.com/questions/3685/where-to-cut-a-dendrogram
Cutting dendrogram at highest level of purity
因此,我一直在阅读DynamicTreeCut算法,以及该算法的Java实现。我理解该算法的工作原理和它在做什么方面,也就是每一步正在发生的事情的逐步说明。但是,我无法理解该算法如何做出任何有意义的事情。我认为我在这里缺少一些关键概念。
通常,该算法从树状图中的“高度序列”迭代。我不确定,“高度序列”是否只是指树状图上沿Y轴的值,即聚类合并发生的各种高度。如果是这样的话,我们可以假设“高度序列”按升序排列。
然后,算法要求选取一个“参考高度”l,并将其从输入的“高度序列”中的每个高度中减去。这将给出一个差分向量(D),用来表示高度序列中每个高度h[i]与参考高度l之间的差异。
接下来,算法尝试找到“转换点”,这些点是差分向量中满足条件D[i] > 0和D[i+1] < 0的点。换句话说,它是在差异向量中,在差异值从正数转变为负数的位置上。
在这里,我完全迷失了。我不明白这些转换点如何有意义。首先,我理解输入的高度序列H只是树状图上Y轴上的值。因此,高度序列H应该按升序排列。因此,差分向量中如何存在从正数到负数的转换点呢?
例如:
假设我们的输入高度序列H为{1, 1.5, 2, 2.5, 3, 7, 9},参考值l为平均高度(即3.7)。如果我们通过将每个高度从l中减去来创建一个差异向量D,则会得到{-2.7, -2.2, -1.7, -1.2, -0.7, 3.3, 5.3}。显然,这里没有过渡点,也永远不可能有过渡点,因为差异向量中没有任何一点满足 D [i] > 0且D [i + 1] <0 ,因为高度序列H 是按升序排列的。所以很明显,我完全误解了该算法中的某些基本概念。也许我没有理解“高度序列”的含义。我认为它只是树状图上的Y轴值,但显然这与算法实际执行的内容毫无关系。不幸的是,作者并没有真正解释“树状图高度序列”的含义,而且在数据科学社区中似乎也没有这种标准术语。
那么,有人能解释一下DynamicTreeCut算法在这里试图实现什么,并指出我的理解错在哪里吗?