需要根据条件向数据框中添加新行。
当前的数据框:
例如:03-01夜班最接近12PM的值是21:46:54。因此需要添加两行。
最终预期的数据框应该是这样的:
非常感谢您的支持!!!!
当前的数据框:
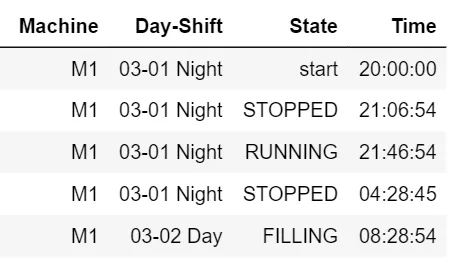
例如:03-01夜班最接近12PM的值是21:46:54。因此需要添加两行。
W25 03-01 Night RUNNING 23:59:59
W25 03-01 Night RUNNING 00:00:01
最终预期的数据框应该是这样的:
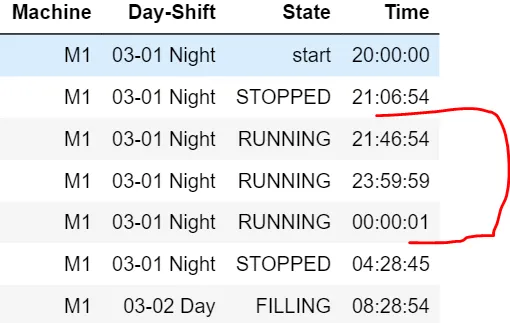
data={'Machine': {0: 'W5', 343: 'W5', 344: 'W5', 586: 'W5', 587: 'W5'}, 'State': {0: 'start', 343: 'STOPPED', 344: 'RUNNING', 586: 'STOPPED', 587: 'MAINT'}, 'Day-Shift': {0: '03-01 Night', 343: '03-01 Night', 344: '03-01 Night', 586: '03-01 Night', 587: '03-01 Night'}, 'Time': {0: Timestamp('2021-03-01 21:00:00'), 343: Timestamp('2021-03-01 22:16:54'), 344: Timestamp('2021-03-01 23:16:54'), 586: Timestamp('2021-03-01 23:48:45'), 587: Timestamp('2021-03-02 02:28:54')}}
非常感谢您的支持!!!!