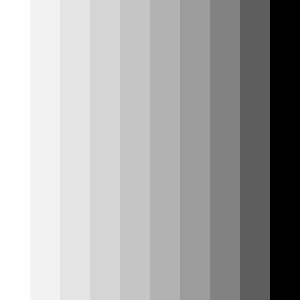简而言之
我测试了其他图像处理库(scikit-image、Pillow和Matlab),但它们都没有返回预期的结果。
我认为这种行为很可能是由于执行双线性插值的方法以获得高效结果或某种约定,而不是我的错误。
我发布了一个示例代码,用双线性插值进行图像调整(当然要检查一切是否正常,我不确定如何正确处理图像索引...),它输出了预期的结果。
部分回答问题。
其他图像处理库的输出是什么?
scikit-image
Python模块scikit-image包含许多图像处理算法。这里是skimage.transform.resize方法(skimage.__version__: 0.12.3)的输出:
代码:
import numpy as np
from skimage.transform import resize
image = np.array( [
[0., 1.],
[0., 1.]
] )
print 'image:\n', image
image_resized = resize(image, (5,5), order=1, mode='constant')
print 'image_resized:\n', image_resized
结果:
image:
[[ 0. 1.]
[ 0. 1.]]
image_resized:
[[ 0. 0.07 0.35 0.63 0.49]
[ 0. 0.1 0.5 0.9 0.7 ]
[ 0. 0.1 0.5 0.9 0.7 ]
[ 0. 0.1 0.5 0.9 0.7 ]
[ 0. 0.07 0.35 0.63 0.49]]
结果:
image:
[[ 0. 1.]
[ 0. 1.]]
image_resized:
[[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]]
结果:
image:
[[ 0. 1.]
[ 0. 1.]]
image_resized:
[[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]
[ 0. 0.1 0.5 0.9 1. ]]
结果:
image:
[[ 0. 1.]
[ 0. 1.]]
image_resized:
[[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]]
结果:
image:
[[ 0. 1.]
[ 0. 1.]]
image_resized:
[[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]
[ 0.3 0.1 0.5 0.9 0.7]]
正如您所见, 默认的调整大小模式(
constant)产生了不同的输出,但边缘模式返回与OpenCV相同的结果。然而,没有一个调整大小模式产生预期的结果。
有关
插值:边缘模式的更多信息。
这张图片总结了我们这种情况下的所有结果:
枕头
枕头
是由Alex Clark和贡献者推出的友好的PIL分支。 PIL是Fredrik Lundh和贡献者开发的Python图像处理库。
PIL.Image.Image.resize怎么样(PIL.__version__:4.0.0)?
代码:
import numpy as np
from PIL import Image
image = np.array( [
[0., 1.],
[0., 1.]
] )
print 'image:\n', image
image_pil = Image.fromarray(image)
image_resized_pil = image_pil.resize((5,5), resample=Image.BILINEAR)
print 'image_resized_pil:\n', np.asarray(image_resized_pil, dtype=np.float)
结果:
image:
[[ 0. 1.]
[ 0. 1.]]
image_resized_pil:
[[ 0. 0.1 0.5 0.89999998 1. ]
[ 0. 0.1 0.5 0.89999998 1. ]
[ 0. 0.1 0.5 0.89999998 1. ]
[ 0. 0.1 0.5 0.89999998 1. ]
[ 0. 0.1 0.5 0.89999998 1. ]]
Pillow 图片调整大小与 OpenCV 库的输出匹配。
Matlab
Matlab 提供了一个名为 Image Processing Toolbox 的工具箱。该工具箱中的函数 imresize 允许调整图像大小。
代码:
image = zeros(2,1,'double');
image(1,2) = 1;
image(2,2) = 1;
image
image_resize = imresize(image, [5 5], 'bilinear')
结果:
image =
0 1
0 1
image_resize =
0 0.1000 0.5000 0.9000 1.0000
0 0.1000 0.5000 0.9000 1.0000
0 0.1000 0.5000 0.9000 1.0000
0 0.1000 0.5000 0.9000 1.0000
0 0.1000 0.5000 0.9000 1.0000
再次强调,这不是使用Matlab得到的期望输出,但与前两个示例结果相同。
自定义双线性图像缩放方法
基本原理
请参阅维基百科上关于双线性插值的更完整信息。
这张图片基本上说明了从2x2图像放大到4x4图像时会发生什么:
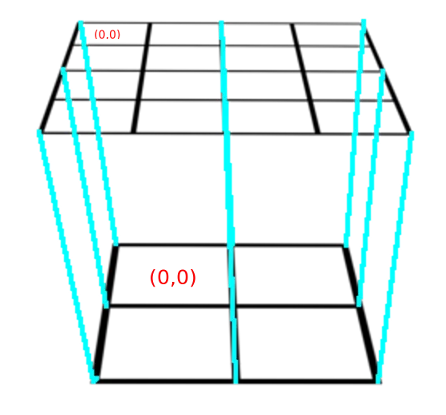
使用最近邻插值,目标像素在(0,0)处将获得源像素在(0,0)处以及(0,1)、(1,0)和(1,1)处的像素值。
使用双线性插值,目标像素在(0,0)处将获得源图像中4个相邻像素的线性组合。
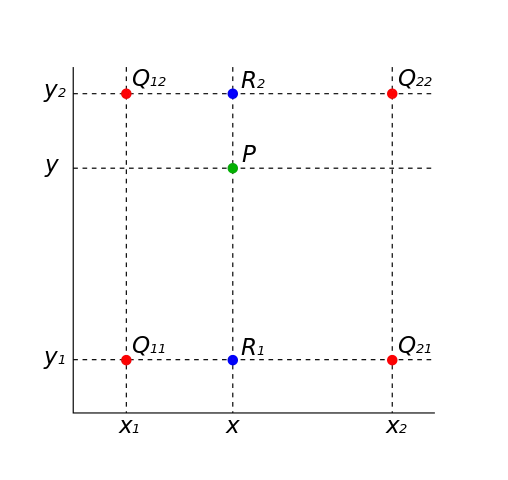
这四个红点表示数据点,绿点是我们想要插值的点。
R1 的计算公式为:R1 = ((x2 – x)/(x2 – x1))*Q11 + ((x – x1)/(x2 – x1))*Q21。
R2 的计算公式为:R2 = ((x2 – x)/(x2 – x1))*Q12 + ((x – x1)/(x2 – x1))*Q22。
最后,P 是 R1 和 R2 的加权平均值:P = ((y2 – y)/(y2 – y1))*R1 + ((y – y1)/(y2 – y1))*R2。
在 [0, 1] 范围内归一化坐标可以简化 公式。
C++ 实现
这篇博客文章(
使用双线性插值调整图像大小)包含用C++编写的代码,用于执行带有双线性插值的图像调整。
这是我自己对该代码进行的改编(与原始代码相比索引进行了一些修改,
不确定是否正确),以便与
cv::Mat一起使用。
#include <iostream>
#include <opencv2/core.hpp>
float lerp(const float A, const float B, const float t) {
return A * (1.0f - t) + B * t;
}
template <typename Type>
Type resizeBilinear(const cv::Mat &src, const float u, const float v, const float xFrac, const float yFrac) {
int u0 = (int) u;
int v0 = (int) v;
int u1 = (std::min)(src.cols-1, (int) u+1);
int v1 = v0;
int u2 = u0;
int v2 = (std::min)(src.rows-1, (int) v+1);
int u3 = (std::min)(src.cols-1, (int) u+1);
int v3 = (std::min)(src.rows-1, (int) v+1);
float col0 = lerp(src.at<Type>(v0, u0), src.at<Type>(v1, u1), xFrac);
float col1 = lerp(src.at<Type>(v2, u2), src.at<Type>(v3, u3), xFrac);
float value = lerp(col0, col1, yFrac);
return cv::saturate_cast<Type>(value);
}
template <typename Type>
void resize(const cv::Mat &src, cv::Mat &dst) {
float scaleY = (src.rows - 1) / (float) (dst.rows - 1);
float scaleX = (src.cols - 1) / (float) (dst.cols - 1);
for (int i = 0; i < dst.rows; i++) {
float v = i * scaleY;
float yFrac = v - (int) v;
for (int j = 0; j < dst.cols; j++) {
float u = j * scaleX;
float xFrac = u - (int) u;
dst.at<Type>(i, j) = resizeBilinear<Type>(src, u, v, xFrac, yFrac);
}
}
}
void resize(const cv::Mat &src, cv::Mat &dst, const int width, const int height) {
if (width < 2 || height < 2 || src.cols < 2 || src.rows < 2) {
std::cerr << "Too small!" << std::endl;
return;
}
dst = cv::Mat::zeros(height, width, src.type());
switch (src.type()) {
case CV_8U:
resize<uchar>(src, dst);
break;
case CV_64F:
resize<double>(src, dst);
break;
default:
std::cerr << "Src type is not supported!" << std::endl;
break;
}
}
int main() {
cv::Mat img = (cv::Mat_<double>(2,2) << 0, 1, 0, 1);
std::cout << "img:\n" << img << std::endl;
cv::Mat img_resize;
resize(img, img_resize, 5, 5);
std::cout << "img_resize=\n" << img_resize << std::endl;
return EXIT_SUCCESS;
}
它产生:
img:
[0, 1;
0, 1]
img_resize=
[0, 0.25, 0.5, 0.75, 1;
0, 0.25, 0.5, 0.75, 1;
0, 0.25, 0.5, 0.75, 1;
0, 0.25, 0.5, 0.75, 1;
0, 0.25, 0.5, 0.75, 1]
结论
在我看来,OpenCV的resize()函数不太可能出错,因为我测试的其他图像处理库都没有产生预期输出,并且可以使用良好的参数产生相同的OpenCV输出。
我测试了两个Python模块(scikit-image和Pillow),因为它们易于使用并且专注于图像处理。我还能够使用Matlab及其图像处理工具箱进行测试。
对于图像调整大小的双线性插值的粗略自定义实现产生了预期结果。对我来说,有两种可能解释这种行为:
- 这些图像处理库使用的方法固有差异而不是bug(也许它们使用一种方法以某种损失高效地调整图像大小,与严格的双线性实现相比?)
- 这是一种合适地插值但排除边框的约定吗?
这些库是开源的,人们可以探索它们的源代码以了解差异来自何处。
linked answer显示插值仅在两个原始蓝点之间起作用,但我无法解释为什么会出现这种情况。
为什么选择这个答案?
这个回答虽然只部分回答了问题,但是对我总结这个话题所找到的少量资料非常有帮助。我相信它也可以帮助其他可能会遇到同样问题的人。