我正在尝试实现一个双向图搜索。据我了解,我应该将两个广度优先搜索合并起来,一个从起点(或根节点)开始,另一个从目标(或结束)节点开始。当两个广度优先搜索在同一个顶点处“相遇”时,双向搜索终止。
您能否提供一个代码示例(如果可能的话,用Java编写),或者提供一些相关的链接以获取双向图搜索的代码?
我正在尝试实现一个双向图搜索。据我了解,我应该将两个广度优先搜索合并起来,一个从起点(或根节点)开始,另一个从目标(或结束)节点开始。当两个广度优先搜索在同一个顶点处“相遇”时,双向搜索终止。
您能否提供一个代码示例(如果可能的话,用Java编写),或者提供一些相关的链接以获取双向图搜索的代码?
Node(在文件Node.java中):import java.util.HashSet;
import java.util.Set;
public class Node<T> {
private final T data; // The data that you want to store in this node.
private final Set<Node> adjacentNodes = new HashSet<>();
// Constructor
public Node(T data) {
this.data = data;
}
// Getters
/*
* Returns the data stored in this node.
* */
public T getData() {
return data;
}
/*
* Returns a set of the adjacent nodes of this node.
* */
public Set<Node> getAdjacentNodes() {
return adjacentNodes;
}
// Setters
/*
* Attempts to add node to the set of adjacent nodes of this node. If it was not previously added, it is added, and
* true is returned. If it was previously added, it returns false.
* */
public boolean addAdjacent(Node node) {
return adjacentNodes.add(node);
}
}
然后双向搜索算法(定义在文件BidirectionalSearch.java中)将类似于以下内容:
import java.util.HashSet;
import java.util.Queue;
import java.util.Set;
import java.util.LinkedList;
public class BidirectionalSearch {
/*
* Returns true if a path exists between Node a and b, false otherwise.
* */
public static boolean pathExists(Node a, Node b) {
// LinkedList implements the Queue interface, FIFO queue operations (e.g., add and poll).
// Queue to hold the paths from Node a.
Queue<Node> queueA = new LinkedList<>();
// Queue to hold the paths from Node a.
Queue<Node> queueB = new LinkedList<>();
// A set of visited nodes starting from Node a.
Set<Node> visitedA = new HashSet<>();
// A set of visited nodes starting from Node b.
Set<Node> visitedB = new HashSet<>();
visitedA.add(a);
visitedB.add(b);
queueA.add(a);
queueB.add(b);
// Both queues need to be empty to exit the while loop.
while (!queueA.isEmpty() || !queueB.isEmpty()) {
if (pathExistsHelper(queueA, visitedA, visitedB)) {
return true;
}
if (pathExistsHelper(queueB, visitedB, visitedA)) {
return true;
}
}
return false;
}
private static boolean pathExistsHelper(Queue<Node> queue,
Set<Node> visitedFromThisSide,
Set<Node> visitedFromThatSide) {
if (!queue.isEmpty()) {
Node next = queue.remove();
Set<Node> adjacentNodes = next.getAdjacentNodes();
for (Node adjacent : adjacentNodes) {
// If the visited nodes, starting from the other direction,
// contain the "adjacent" node of "next", then we can terminate the search
if (visitedFromThatSide.contains(adjacent)) {
return true;
} else if (visitedFromThisSide.add(adjacent)) {
queue.add(adjacent);
}
}
}
return false;
}
public static void main(String[] args) {
// Test here the implementation above.
}
}
逻辑: 在正常情况下,BFS是递归的。但在这里,我们不能递归使用它,因为如果我们从递归开始,那么它将覆盖所有节点从一侧(开始或结束),并且只有在找不到终点或找到终点时才会停止。
因此,为了进行双向搜索,下面的例子将解释逻辑:
/*
Let's say this is the graph
2------5------8
/ |
/ |
/ |
1---3------6------9
\ |
\ |
\ |
4------7------10
We want to find the path between nodes 1 and 9. In order to do this we will need 2 DS, one for recording the path form beginning and other from end:*/
ArrayList<HashMap<Integer, LinkedList<Node<Integer>>>> startTrav = new ArrayList<>();
ArrayList<HashMap<Integer, LinkedList<Node<Integer>>>> endTrav = new ArrayList<>();
/*Before starting the loop, initialise these with the values shown below:
startTrav --> index=0 --> <1, {1}>
endTrav --> index=0 --> <9, {9}>
Note here that in the HashMap, the key is the node that we have reached and the value is a linkedList containing the path used to reach to that node.
Now inside the loop we will start traversal on startTrav 1st. We will traverse it from index 0 to 0, and while traversing what ever children are there for the node under process, we will add in startTrav. So startTrav will transform like:
startTrav --> index=0 --> <1, {1}>
startTrav --> index=1 --> <2, {1,2}>
startTrav --> index=2 --> <3, {1,3}>
startTrav --> index=3 --> <4, {1,4}>
Now we will check for collision, i.e if either of nodes that we have covered in startTrav are found in endTrav (i.e if either of 1,2,3,4 is present in endTrav's list = 9). The answer is no, so continue loop.
Now do the same from endTrav
endTrav --> index=0 --> <9, {9}>
endTrav --> index=1 --> <8, {9,8}>
endTrav --> index=2 --> <6, {9,6}>
endTrav --> index=3 --> <10, {9,10}>
Now again we will check for collision, i.e if either of nodes that we have covered in startTrav are found in endTrav (i.e if either of 1,2,3,4 is present in endTrav's list = 9,8,6,10). The answer is no so continue loop.
// end of 1st iteration of while loop
// beginning of 2nd iteration of while loop
startTrav --> index=0 --> <1, {1}>
startTrav --> index=1 --> <2, {1,2}>
startTrav --> index=2 --> <3, {1,3}>
startTrav --> index=3 --> <4, {1,4}>
startTrav --> index=4 --> <5, {1,2,5}>
startTrav --> index=5 --> <6, {1,3,6}>
startTrav --> index=6 --> <7, {1,4,7}>
Now again we will check for collision, i.e if either of nodes that we have covered in startTrav are found in endTrav (i.e if either of 1,2,3,4,5,6,7 is present in endTrav's list = 9,8,6,10). The answer is yes. Colission has occurred on node 6. Break the loop now.
Now pick the path to 6 from startTrav and pick the path to 6 from endTrav and merge the 2.*/
代码如下:
class Node<T> {
public T value;
public LinkedList<Node<T>> nextNodes = new LinkedList<>();
}
class Graph<T>{
public HashMap<Integer, Node<T>> graph=new HashMap<>();
}
public class BiDirectionalBFS {
public LinkedList<Node<Integer>> findPath(Graph<Integer> graph, int startNode, int endNode) {
if(!graph.graph.containsKey(startNode) || !graph.graph.containsKey(endNode)) return null;
if(startNode==endNode) {
LinkedList<Node<Integer>> ll = new LinkedList<>();
ll.add(graph.graph.get(startNode));
return ll;
}
ArrayList<HashMap<Integer, LinkedList<Node<Integer>>>> startTrav = new ArrayList<>();
ArrayList<HashMap<Integer, LinkedList<Node<Integer>>>> endTrav = new ArrayList<>();
boolean[] traversedNodesFromStart = new boolean[graph.graph.size()];
boolean[] traversedNodesFromEnd = new boolean[graph.graph.size()];
addDetailsToAL(graph, startNode, startTrav, traversedNodesFromStart, null);
addDetailsToAL(graph, endNode, endTrav, traversedNodesFromEnd, null);
int collision = -1, startIndex=0, endIndex=0;
while (startTrav.size()>startIndex && endTrav.size()>endIndex) {
// Cover all nodes in AL from start and add new
int temp=startTrav.size();
for(int i=startIndex; i<temp; i++) {
recordAllChild(graph, startTrav, i, traversedNodesFromStart);
}
startIndex=temp;
//check collision
if((collision = checkColission(traversedNodesFromStart, traversedNodesFromEnd))!=-1) {
break;
}
//Cover all nodes in AL from end and add new
temp=endTrav.size();
for(int i=endIndex; i<temp; i++) {
recordAllChild(graph, endTrav, i, traversedNodesFromEnd);
}
endIndex=temp;
//check collision
if((collision = checkColission(traversedNodesFromStart, traversedNodesFromEnd))!=-1) {
break;
}
}
LinkedList<Node<Integer>> pathFromStart = null, pathFromEnd = null;
if(collision!=-1) {
for(int i =0;i<traversedNodesFromStart.length && (pathFromStart==null || pathFromEnd==null); i++) {
if(pathFromStart==null && startTrav.get(i).keySet().iterator().next()==collision) {
pathFromStart=startTrav.get(i).get(collision);
}
if(pathFromEnd==null && endTrav.get(i).keySet().iterator().next()==collision) {
pathFromEnd=endTrav.get(i).get(collision);
}
}
pathFromEnd.removeLast();
ListIterator<Node<Integer>> li = pathFromEnd.listIterator();
while(li.hasNext()) li.next();
while(li.hasPrevious()) {
pathFromStart.add(li.previous());
}
return pathFromStart;
}
return null;
}
private void recordAllChild(Graph<Integer> graph, ArrayList<HashMap<Integer, LinkedList<Node<Integer>>>> listToAdd, int index, boolean[] traversedNodes) {
HashMap<Integer, LinkedList<Node<Integer>>> record=listToAdd.get(index);
Integer recordKey = record.keySet().iterator().next();
for(Node<Integer> child:graph.graph.get(recordKey).nextNodes) {
if(traversedNodes[child.value]!=true) { addDetailsToAL(graph, child.getValue(), listToAdd, traversedNodes, record.get(recordKey));
}
}
}
private void addDetailsToAL(Graph<Integer> graph, Integer node, ArrayList<HashMap<Integer, LinkedList<Node<Integer>>>> startTrav,
boolean[] traversalArray, LinkedList<Node<Integer>> oldLLContent) {
LinkedList<Node<Integer>> ll = oldLLContent==null?new LinkedList<>() : new LinkedList<>(oldLLContent);
ll.add(graph.graph.get(node));
HashMap<Integer, LinkedList<Node<Integer>>> hm = new HashMap<>();
hm.put(node, ll);
startTrav.add(hm);
traversalArray[node]=true;
}
private int checkColission(boolean[] start, boolean[] end) {
for (int i=0; i<start.length; i++) {
if(start[i] && end[i]) {
return i;
}
}
return -1;
}
}
通过数组可以采用更加简洁易懂的方法。我们将替换复杂的数据结构:
ArrayList<HashMap<Integer, LinkedList<Node<Integer>>>>
标签。
LinkedList<Node<Integer>>[]
LinkedList<Node<Integer>>
这将用于存储子节点,就像树的层次遍历一样。最后,我们为了存储从结束位置遍历的路径,将以相反的顺序存储它,以便在合并时,我们不需要颠倒第二个数组中的元素。其代码如下:
class Node<T> {
public T value;
public LinkedList<Node<T>> nextNodes = new LinkedList<>();
}
class Graph<T>{
public HashMap<Integer, Node<T>> graph=new HashMap<>();
}
public class BiDirectionalBFS {
private LinkedList<Node<Integer>> findPathUsingArrays(Graph<Integer> graph, int startNode, int endNode) {
if(!graph.graph.containsKey(startNode) || !graph.graph.containsKey(endNode)) return null;
if(startNode==endNode) {
LinkedList<Node<Integer>> ll = new LinkedList<>();
ll.add(graph.graph.get(startNode));
return ll;
}
LinkedList<Node<Integer>>[] startTrav = new LinkedList[graph.graph.size()];
LinkedList<Node<Integer>>[] endTrav = new LinkedList[graph.graph.size()];
LinkedList<Node<Integer>> traversedNodesFromStart = new LinkedList<>();
LinkedList<Node<Integer>> traversedNodesFromEnd = new LinkedList<>();
addToDS(graph, traversedNodesFromStart, startTrav, startNode);
addToDS(graph, traversedNodesFromEnd, endTrav, endNode);
int collision = -1;
while (traversedNodesFromStart.size()>0 && traversedNodesFromEnd.size()>0) {
// Cover all nodes in LL from start and add new
recordAllChild(traversedNodesFromStart.size(), traversedNodesFromStart, startTrav, true);
//check collision
if((collision = checkColission(startTrav, endTrav))!=-1) {
break;
}
//Cover all nodes in LL from end and add new
recordAllChild(traversedNodesFromEnd.size(), traversedNodesFromEnd, endTrav, false);
//check collision
if((collision = checkColission(startTrav, endTrav))!=-1) {
break;
}
}
if(collision!=-1) {
endTrav[collision].removeFirst();
startTrav[collision].addAll(endTrav[collision]);
return startTrav[collision];
}
return null;
}
private void recordAllChild(int temp, LinkedList<Node<Integer>> traversedNodes, LinkedList<Node<Integer>>[] travArr, boolean addAtLast) {
while (temp>0) {
Node<Integer> node = traversedNodes.remove();
for(Node<Integer> child : node.nextNodes) {
if(travArr[child.value]==null) {
traversedNodes.add(child);
LinkedList<Node<Integer>> ll=new LinkedList<>(travArr[node.value]);
if(addAtLast) {
ll.add(child);
} else {
ll.addFirst(child);
}
travArr[child.value]=ll;
traversedNodes.add(child);
}
}
temp--;
}
}
private int checkColission(LinkedList<Node<Integer>>[] startTrav, LinkedList<Node<Integer>>[] endTrav) {
for (int i=0; i<startTrav.length; i++) {
if(startTrav[i]!=null && endTrav[i]!=null) {
return i;
}
}
return -1;
}
private void addToDS(Graph<Integer> graph, LinkedList<Node<Integer>> traversedNodes, LinkedList<Node<Integer>>[] travArr, int node) {
LinkedList<Node<Integer>> ll = new LinkedList<>();
ll.add(graph.graph.get(node));
travArr[node]=ll;
traversedNodes.add(graph.graph.get(node));
}
}
试试这个:
Graph.java
import java.util.HashSet;
import java.util.Set;
public class Graph<T> {
private T value;
private Set<Graph> adjacents = new HashSet<>();
private Set<String> visitors = new HashSet<>();
public Graph(T value) {
this.value = value;
}
public T getValue() {
return value;
}
public void addAdjacent(Graph adjacent) {
this.adjacents.add(adjacent);
}
public Set<Graph> getAdjacents() {
return this.adjacents;
}
public void setVisitor(String visitor) {
this.visitors.add(visitor);
}
public boolean hasVisitor(String visitor) {
return this.visitors.contains(visitor);
}
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
sb.append("Value [").append(value).append("] visitors[");
if (!visitors.isEmpty()) {
for (String visitor : visitors) {
sb.append(visitor).append(",");
}
}
sb.append("]");
return sb.toString().replace(",]", "]");
}
}
GraphHelper.java
import java.util.Iterator;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Set;
public class GraphHelper {
// implements singleton pattern
private static GraphHelper instance;
private GraphHelper() {
}
/**
* @return the instance
*/
public static GraphHelper getInstance() {
if (instance == null)
instance = new GraphHelper();
return instance;
}
public boolean isRoute(Graph gr1, Graph gr2) {
Queue<Graph> queue1 = new LinkedList<>();
Queue<Graph> queue2 = new LinkedList<>();
addToQueue(queue1, gr1, "1");
addToQueue(queue2, gr2, "2");
while (!queue1.isEmpty() || !queue2.isEmpty()) {
if (!queue1.isEmpty()) {
Graph gAux1 = queue1.remove();
Iterator<Graph> it1 = gAux1.getAdjacents().iterator();
while (it1.hasNext()) {
Graph adj1 = it1.next();
System.out.println("adj1 " + adj1);
if (adj1.hasVisitor("2"))
return true;
else if (!adj1.hasVisitor("1"))
addToQueue(queue1, adj1, "1");
}
}
if (!queue2.isEmpty()) {
Graph gAux2 = queue2.remove();
Iterator<Graph> it2 = gAux2.getAdjacents().iterator();
while (it2.hasNext()) {
Graph adj2 = it2.next();
System.out.println("adj2 " + adj2);
if (adj2.hasVisitor("1"))
return true;
else if (!adj2.hasVisitor("2"))
addToQueue(queue2, adj2, "2");
}
}
}
return false;
}
private void addToQueue(Queue<Graph> queue, Graph gr, String visitor) {
gr.setVisitor(visitor);
queue.add(gr);
}
}
GraphTest.java
public class GraphTest {
private GraphHelper helper = GraphHelper.getInstance();
public static void main(String[] args) {
GraphTest test = new GraphTest();
test.testIsRoute();
}
public void testIsRoute() {
Graph commonGraph = new Graph<String>("z");
System.out
.println("Expected true, result [" + helper.isRoute(graph1(commonGraph), graph2(commonGraph)) + "]\n");
commonGraph = new Graph<String>("z");
System.out.println("Expected false, result [" + helper.isRoute(graph1(commonGraph), graph2(null)) + "]\n");
}
private Graph graph1(Graph commonGraph) {
Graph main = new Graph<String>("a");
Graph graphb = new Graph<String>("b");
Graph graphc = new Graph<String>("c");
Graph graphd = new Graph<String>("d");
Graph graphe = new Graph<String>("e");
graphb.addAdjacent(graphc);
graphb.addAdjacent(graphe);
if (commonGraph != null)
graphb.addAdjacent(commonGraph);
graphd.addAdjacent(graphc);
graphd.addAdjacent(graphe);
graphd.addAdjacent(main);
main.addAdjacent(graphb);
main.addAdjacent(graphd);
return main;
}
private Graph graph2(Graph commonGraph) {
Graph main = new Graph<String>("f");
Graph graphg = new Graph<String>("g");
Graph graphh = new Graph<String>("h");
Graph graphi = new Graph<String>("i");
Graph graphj = new Graph<String>("j");
graphg.addAdjacent(graphh);
graphg.addAdjacent(graphj);
if (commonGraph != null)
graphg.addAdjacent(commonGraph);
graphi.addAdjacent(graphh);
graphi.addAdjacent(graphj);
graphi.addAdjacent(main);
main.addAdjacent(graphg);
main.addAdjacent(graphi);
return main;
}
}
public class GraphNode {
public Integer value;
public GraphNode[] nodes;
public boolean markedsource = false;
public boolean markedtarget = false;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
GraphNode graphNode = (GraphNode) o;
return Objects.equals(value, graphNode.value);
}
}
boolean found = 双向搜索(source, target);
// .....
private static boolean bidirectionalSearch(GraphNode sourceNode, GraphNode targetNode) {
HashSet<GraphNode> sourceSet = new HashSet<>();
sourceSet.add(sourceNode);
HashSet<GraphNode> targetSet = new HashSet<>();
targetSet.add(targetNode);
return bidirectionalSearch(sourceSet, targetSet, sourceNode, targetNode);
}
private static boolean bidirectionalSearch(Set<GraphNode> sourceSet, Set<GraphNode> targetSet, GraphNode sourceNode, GraphNode targetNode) {
Set<GraphNode> intersection = sourceSet.stream().filter(targetSet::contains).collect(Collectors.toSet());
if (!intersection.isEmpty()) {
System.out.println("intersection found at: " + intersection.iterator().next().value);
return true;
} else if (sourceSet.contains(targetNode) || targetSet.contains(sourceNode)) {
return true;
} else if (sourceSet.isEmpty() && targetSet.isEmpty()) {
return false;
}
sourceSet = sourceSet.stream().flatMap(BidirectionalSearch::getGraphNodeStreamSource)
.collect(Collectors.toSet());
targetSet = targetSet.stream().flatMap(
BidirectionalSearch::getGraphNodeStreamTarget).collect(Collectors.toSet());
return bidirectionalSearch(sourceSet, targetSet, sourceNode, targetNode);
}
private static Stream<GraphNode> getGraphNodeStreamSource(GraphNode n) {
if (n.nodes != null)
return Arrays.stream(n.nodes).filter(b -> {
if (!b.markedsource) {
b.markedsource = true;
return true;
} else {
return false;
}
});
else {
return null;
}
}
private static Stream<GraphNode> getGraphNodeStreamTarget(GraphNode n) {
if (n.nodes != null)
return Arrays.stream(n.nodes).filter(b -> {
if (!b.markedtarget) {
b.markedtarget = true;
return true;
} else {
return false;
}
});
else {
return null;
}
}
这是通过扩展输入集合中相邻节点来考虑每次迭代的sourceSet和targetSet,从而实现的。
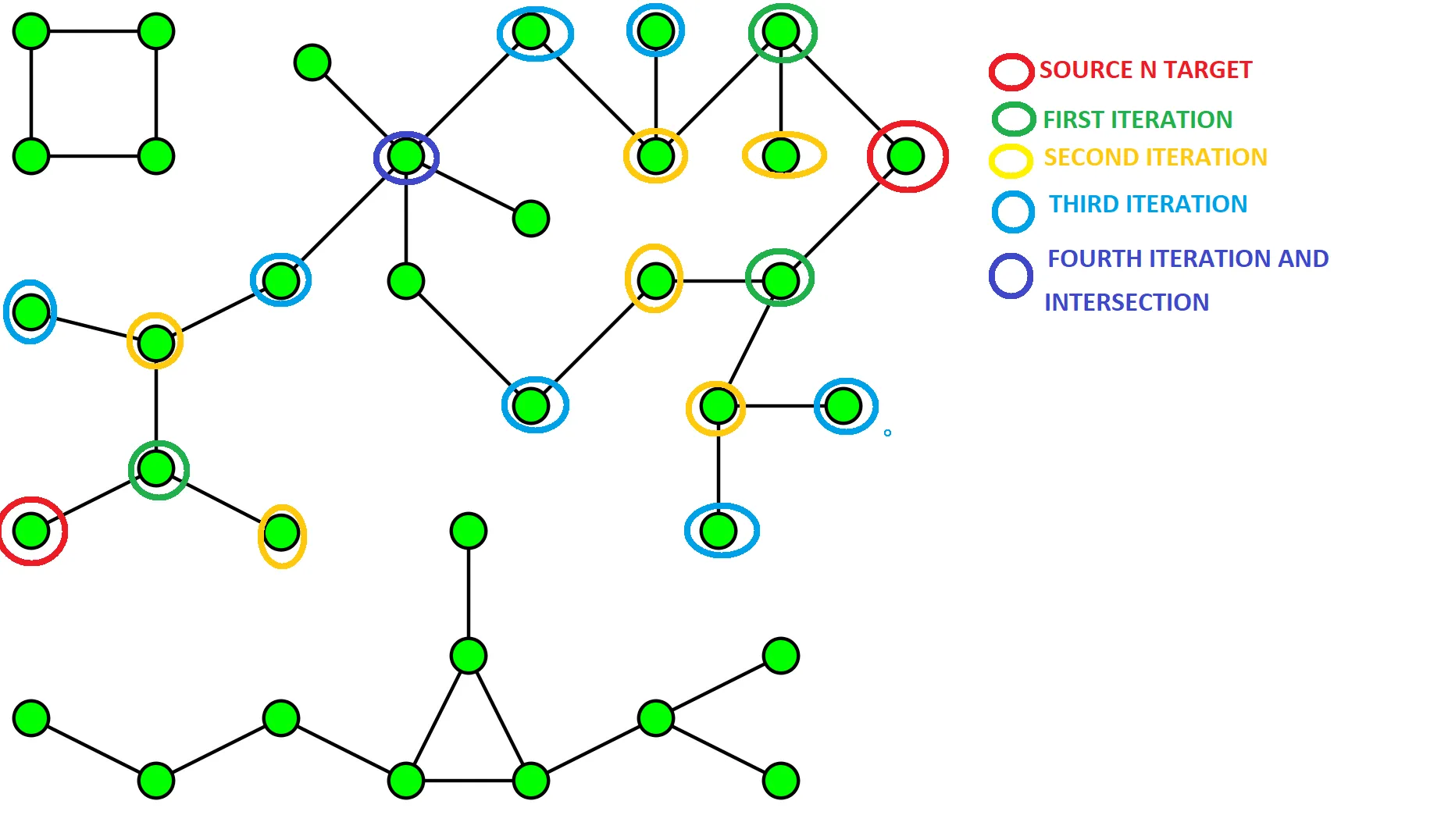
现在让我们看看相对于标准的BFS(广度优先搜索)的优势。如果K是每个节点的最大数字,源节点到目标节点的最短路径为D,那么可以将时间复杂度从O(k^D)缩短到2*O(K^(D/2))。
我们还必须考虑两个SET的额外空间以及每次迭代检查交集所需的时间。
使用标准BFS,您需要一个QUEUE,在迭代K时将具有节点的所有k^d元素的最坏情况。在这种情况下,我们将拥有k^d/2的两个集合。
pathExistsHelper中,每个相邻的节点都立即添加回队列。 - Yehuda Shapira