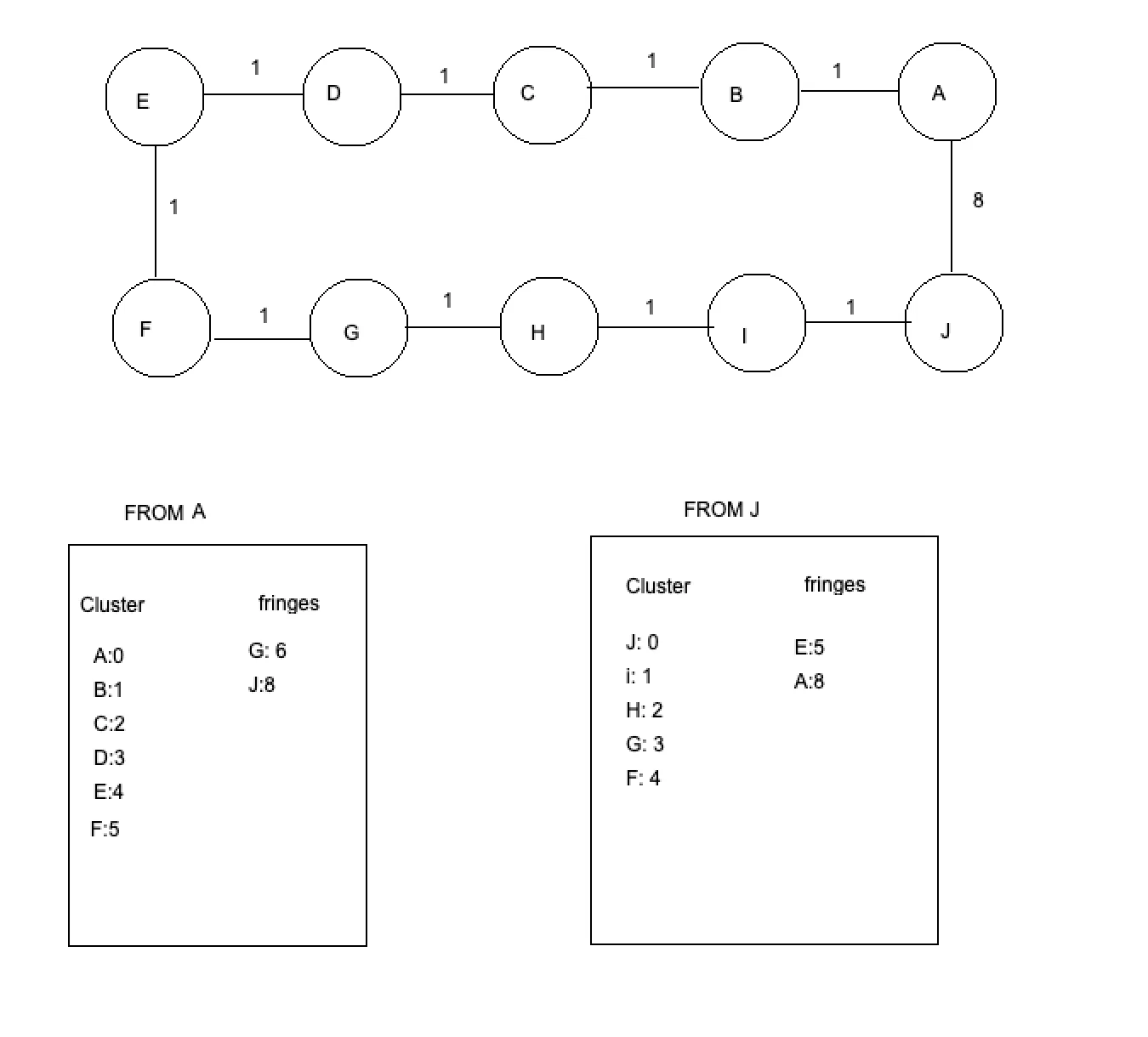
我正在实现一个双向Dijkstra算法,但是我不理解各种停止条件的实现方式。以这个图为例,我们从节点A开始,目标是节点J。下面列出了算法停止时已处理的簇(cluster)和松弛(relaxed)的节点:
即使在这个Java实现中,coderodde的Github代码中,Dijkstra的双向算法的停止条件也是:
这个算法会在前向队列和后向队列中顶部节点的权值之和至少达到目前为止的最佳路径长度时停止。但这并不能返回正确的最短路径。因为在这种情况下,节点G(6)和E(5)的权值总和为11,这比目前为止的长度为9的最佳路径更长。
我不明白这两个看似都是停止条件的方法都会得出错误的最短路径。我不确定我哪里理解有误。
Dijkstra双向算法的一个好的停止条件是什么?此外,双向A*的停止条件是什么?
即使在这个Java实现中,coderodde的Github代码中,Dijkstra的双向算法的停止条件也是:
double mtmp = DISTANCEA.get(OPENA.min()) +
DISTANCEB.get(OPENB.min());
if (mtmp >= bestPathLength) return PATH;
这个算法会在前向队列和后向队列中顶部节点的权值之和至少达到目前为止的最佳路径长度时停止。但这并不能返回正确的最短路径。因为在这种情况下,节点G(6)和E(5)的权值总和为11,这比目前为止的长度为9的最佳路径更长。
我不明白这两个看似都是停止条件的方法都会得出错误的最短路径。我不确定我哪里理解有误。
Dijkstra双向算法的一个好的停止条件是什么?此外,双向A*的停止条件是什么?