我有一个时间序列的数据框,这个数据框非常大,并且在两列(“湿度”和“压力”)中包含一些缺失值。我想以聪明的方式填补这些缺失值,例如使用最近邻的值或前后时间戳的平均值。有没有简单的方法可以做到这一点?我已经尝试过使用fancyimpute,但是数据集包含约180000个示例并且会出现内存错误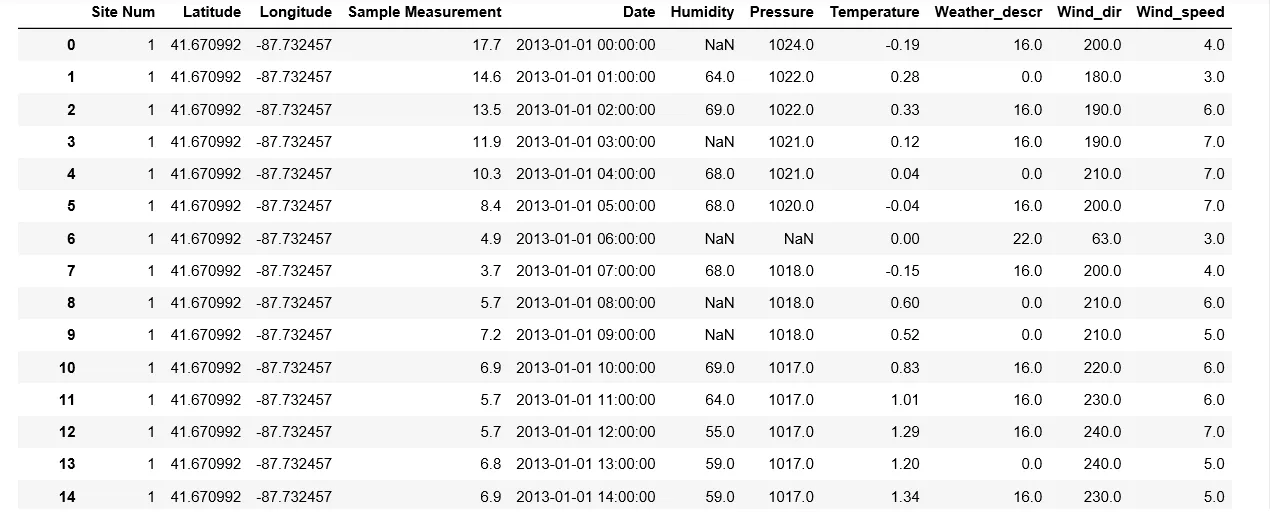
在Python中处理时间序列缺失值
25
- Marco
2
你能否将你的DataFrame的几行作为文本发布,而不是作为图片呢? - Peter Leimbigler
这在很大程度上取决于您想要应用的插补方法。您是否可以简单地提取适用列并在该数据框上进行插补?然后将这些值复制回原始表格。
否则,您尝试过哪些其他方法?简单的浏览器搜索会出现十几个看起来非常有用的结果。 - Prune
4个回答
31
考虑使用 interpolate (Series-DataFrame)。该示例展示了如何使用直线填补任意大小的间隙:
df = pd.DataFrame({'date': pd.date_range(start='2013-01-01', periods=10, freq='H'), 'value': range(10)})
df.loc[2:3, 'value'] = np.nan
df.loc[6, 'value'] = np.nan
df
date value
0 2013-01-01 00:00:00 0.0
1 2013-01-01 01:00:00 1.0
2 2013-01-01 02:00:00 NaN
3 2013-01-01 03:00:00 NaN
4 2013-01-01 04:00:00 4.0
5 2013-01-01 05:00:00 5.0
6 2013-01-01 06:00:00 NaN
7 2013-01-01 07:00:00 7.0
8 2013-01-01 08:00:00 8.0
9 2013-01-01 09:00:00 9.0
df['value'].interpolate(method='linear', inplace=True)
date value
0 2013-01-01 00:00:00 0.0
1 2013-01-01 01:00:00 1.0
2 2013-01-01 02:00:00 2.0
3 2013-01-01 03:00:00 3.0
4 2013-01-01 04:00:00 4.0
5 2013-01-01 05:00:00 5.0
6 2013-01-01 06:00:00 6.0
7 2013-01-01 07:00:00 7.0
8 2013-01-01 08:00:00 8.0
9 2013-01-01 09:00:00 9.0
- Peter Leimbigler
4
5时间序列并非线性。例如考虑一年中的温度变化,它遵循正弦运动规律,并受到多种因素的影响:1. 季节性 2. 趋势性 3. 其他随机因素。在 "R" 中有一个名为[imputeTS]的包(https://cran.r-project.org/web/packages/imputeTS/imputeTS.pdf)可以处理这方面的工作,但我不知道有没有Python的等效包。 - Mohammad ElNesr
8我认为我们应该使用
method ='time' 而不是 method ='linear'。 - Mohammad ElNesr1感谢@MohammadElNesr的贡献。那帮了我很多。 - Behrouz Beheshti
1@MohammadElNesr,感谢您添加关于
method='time' 的信息。我使用线性进展 range(10) 作为简单的示例,但任何值序列都可以用来证明,如果日期系列像原始问题中一样均匀间隔,那么 method='linear' 和 method='time' 之间没有区别。 - Peter Leimbigler9
插值和Filna:
由于这是时间序列问题,我将在答案中使用输出图像进行解释:
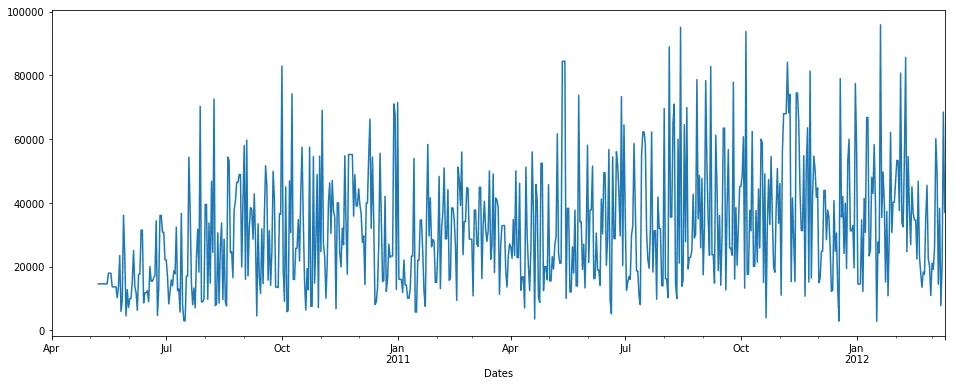
假设我们拥有以下时间序列数据:(x轴表示天数,y轴表示数量)
pdDataFrame.set_index('Dates')['QUANTITY'].plot(figsize = (16,6))
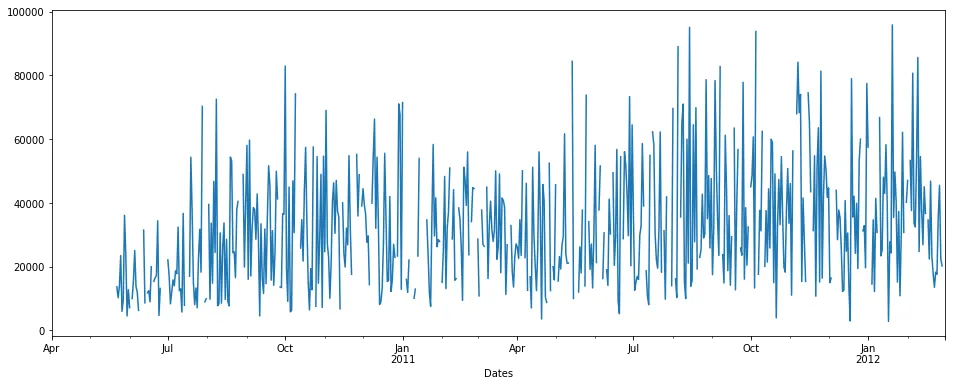
我们可以看到时间序列中有一些NaN数据。NaN的百分比为19.4%。现在我们想要填补空缺/NaN值。
我将尝试展示插值和filna方法填充数据中的NaN值的输出。
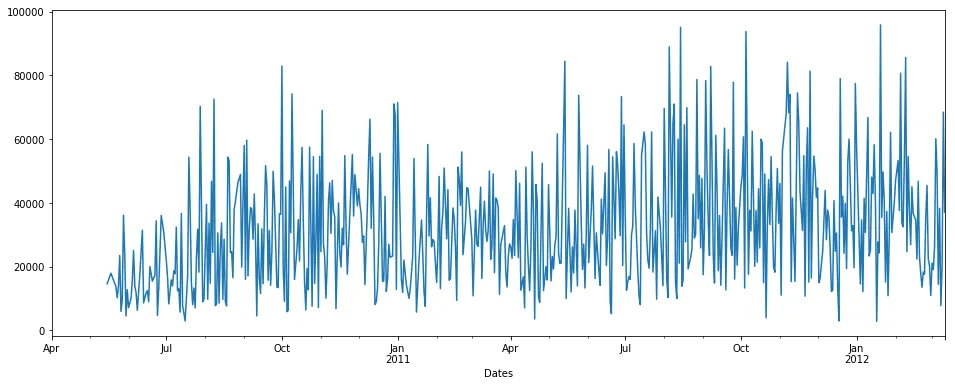
interpolate() :
首先,我们将使用插值方法:
pdDataFrame.set_index('Dates')['QUANTITY'].interpolate(method='linear').plot(figsize = (16,6))
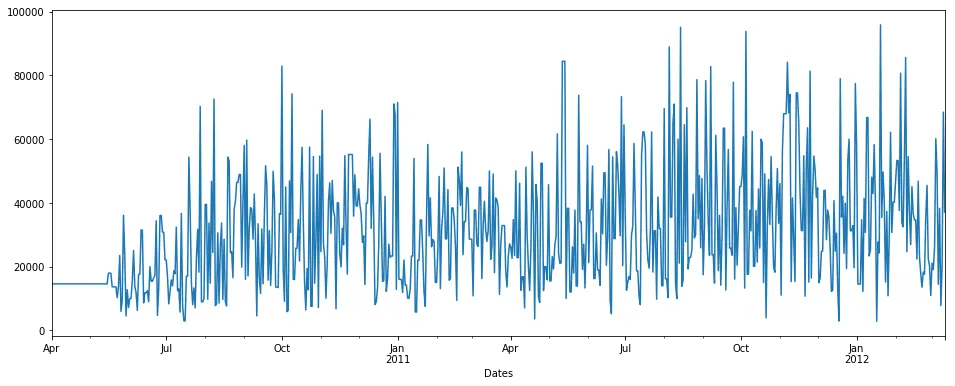
使用向后填充方法的fillna()。
pdDataFrame.set_index('Dates')['QUANTITY'].fillna(value=None, method='backfill', axis=None, limit=None, downcast=None).plot(figsize = (16,6))
使用后向填充方法和 limit = 7 进行 fillna() 填充
limit:这是连续 NaN 值的最大数量,用于进行向前或向后填充。换句话说,如果存在具有超过此连续 NaN 数量的间隙,则只会部分填充。
pdDataFrame.set_index('Dates')['QUANTITY'].fillna(value=None, method='backfill', axis=None, limit=7, downcast=None).plot(figsize = (16,6))
有关这些函数的更多详细信息,请参阅以下链接:
1. Filna: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.fillna.html#pandas.Series.fillna 2. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.interpolate.html 还有一个库:impyute,您可以查看。有关此库的更多详细信息,请参阅此链接:https://pypi.org/project/impyute/
- Yogesh Awdhut Gadade
5
您可以像这样使用
rolling:frame = pd.DataFrame({'Humidity':np.arange(50,64)})
frame.loc[[3,7,10,11],'Humidity'] = np.nan
frame.Humidity.fillna(frame.Humidity.rolling(4,min_periods=1).mean())
输出:
0 50.0
1 51.0
2 52.0
3 51.0
4 54.0
5 55.0
6 56.0
7 55.0
8 58.0
9 59.0
10 58.5
11 58.5
12 62.0
13 63.0
Name: Humidity, dtype: float64
- Scott Boston
0
看起来你的数据是按小时计算的。要不就取前一小时和后一小时的平均值?或者将窗口大小改为2,即前后两个小时的平均值?
使用其他变量进行插补可能会很昂贵,只有在虚拟方法效果不佳(例如引入太多噪音)时才应考虑这些方法。
- Ray
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接