是的,你可以将Fenwick树(二进制索引树)适应为:
- 在O(log n)时间内更新给定索引处的值
- 在O(log n)时间内查询范围内的最小值(平摊)
我们需要2个Fenwick树和一个额外的数组来存储节点的实际值。
假设我们有以下数组:
index 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
value 1 0 2 1 1 3 0 4 2 5 2 2 3 1 0
我们挥动魔杖,以下树形结构出现:
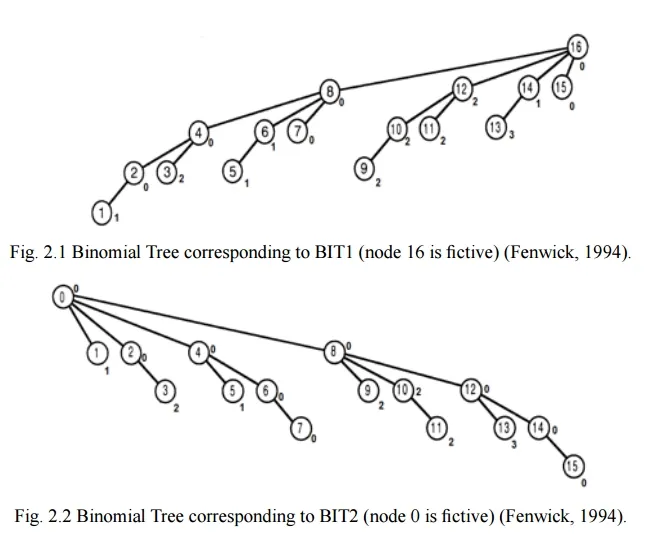
请注意,在这两棵树中,每个节点代表该子树内所有节点的最小值。例如,在BIT2中,节点12的值为0,这是节点12、13、14、15的最小值。
查询
我们可以通过计算多个子树值和一个额外的实际节点值的最小值来高效地查询任何范围内的最小值。例如,范围[2,7]的最小值可以通过取BIT2_Node2(表示节点2,3)和BIT1_Node7(表示节点7)、BIT1_Node6(表示节点5,6)和REAL_4的最小值来确定,从而覆盖[2,7]中的所有节点。但我们如何知道我们要查看哪些子树呢?
Query(int a, int b) {
int val = infinity
int i = a
while (parentOf(i, BIT1) <= b) {
val = min(val, BIT2[i])
i = parentOf(i, BIT1)
}
i = b
while (parentOf(i, BIT2) >= a) {
val = min(val, BIT1[i])
i = parentOf(i, BIT2)
}
val = min(val, REAL[i])
return val
}
数学上可以证明两种遍历最终会到达相同的节点。那个节点是我们范围的一部分,但它不属于我们查看过的任何子树。想象一种情况,即我们范围中唯一的最小值在那个特殊节点中。如果我们没有查找它,我们的算法将会给出错误的结果。这就是为什么我们必须进行一次查找到真实值数组的原因。
为了帮助理解算法,我建议您使用笔和纸模拟它,在上面查找示例树中的数据。例如,对于范围[4,14]的查询将返回值BIT2_4(表示4,5,6,7),BIT1_14(表示13,14),BIT1_12(表示9,10,11,12)和REAL_8的最小值,从而覆盖了所有可能的值[4,14]。
更新
由于一个节点代表其本身和其子节点的最小值,改变一个节点将影响其父节点,但不影响其子节点。因此,要更新一棵树,我们从要修改的节点开始向上移动,一直到虚拟根节点(0或N+1,取决于哪棵树)。
假设我们正在更新一些树中的节点:
- 如果新值<旧值,则总是覆盖该值并向上移动
- 如果新值==旧值,则可以停止,因为不会再有更多的向上级别的变化了
如果新值>旧值,则情况变得有趣。
- 如果旧值仍然存在于该子树中的某个位置,则我们完成了更新
- 否则,我们必须在real[node]和每个tree[child_of_node]之间找到新的最小值,更改tree[node]并向上移动
更新值为v的节点的伪代码:
while (node <= n+1) {
if (v > tree[node]) {
if (oldValue == tree[node]) {
v = min(v, real[node])
for-each child {
v = min(v, tree[child])
}
} else break
}
if (v == tree[node]) break
tree[node] = v
node = parentOf(node, tree)
}
注意oldValue是我们替换的原始值,而v可能会在向上移动树时多次重新赋值。
二进制索引
在我的实验中,范围最小查询(RQM)的速度约为段树实现的两倍,更新略快。这主要原因是使用超级高效的位运算在节点之间移动。它们在这里
非常好地解释了。段树的代码非常简单,因此请考虑性能优势是否真的值得。我Fenwick RMQ的更新方法有40行代码,并花了一些时间来调试。如果有人想要我的代码,我可以将其放在github上。我还编写了测试生成器来确保一切正常。
我从芬兰算法社区获得了理解这个主题和实现它的帮助。图片的来源是
http://ioinformatics.org/oi/pdf/v9_2015_39_44.pdf,但他们归功于Fenwick的1994年论文。